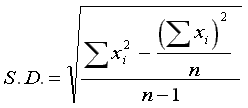
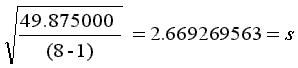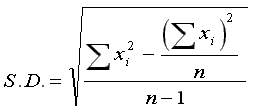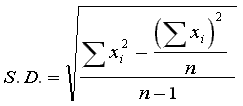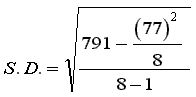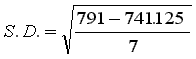| Statistics | Parameters |
| statistics summarize samples | parameters summarize populations |
| you can calculate statistics directly | you can only estimate parameters |
| you use Roman letters for statistics
(x, s, s2) |
you use Greek letters for parameters
( |
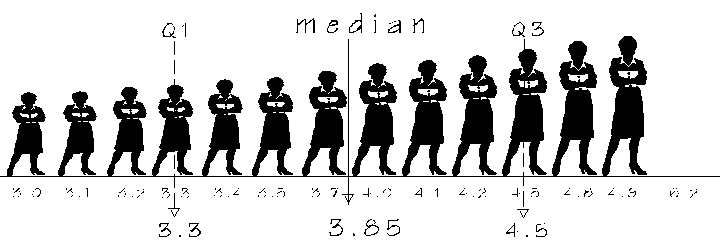
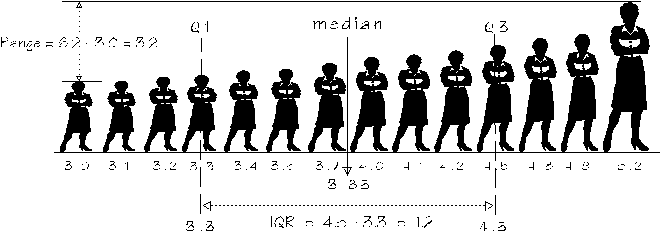

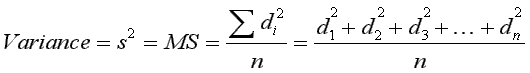
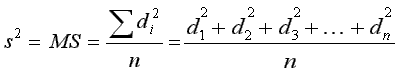
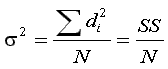
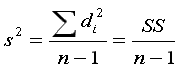
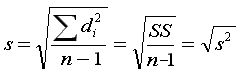
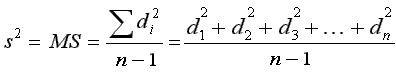
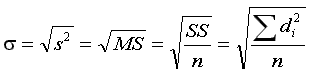
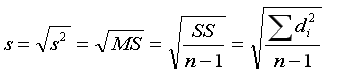
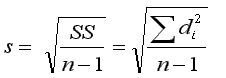 vs.
vs. 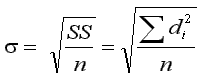
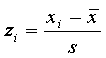
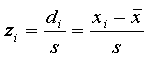
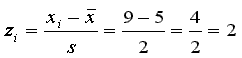
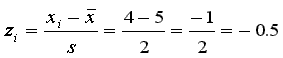
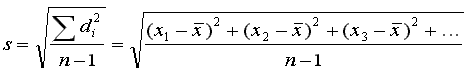
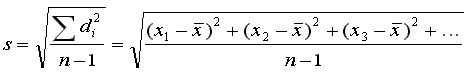
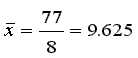 so 7 - 9.625 = -2.625
so 7 - 9.625 = -2.625