Displayed Output
The displayed output from PROC DISCRIM includes the following:
- Class Level Information, including the values of the
classification variable, Variable Name constructed
from each class value, the Frequency and Weight of each value,
its Proportion in the total sample, and the Prior
Probability for each class level.
Optional output includes the following:
- Within-Class SSCP Matrices for each group
- Pooled Within-Class SSCP Matrix
- Between-Class SSCP Matrix
- Total-Sample SSCP Matrix
- Within-Class Covariance Matrices,
St, for each group
- Pooled Within-Class Covariance Matrix, Sp
- Between-Class Covariance Matrix,
equal to the between-class SSCP matrix divided
by n(c-1)/c, where n is the number of
observations and c is the number of classes
- Total-Sample Covariance Matrix
- Within-Class Correlation Coefficients and
 to
test the hypothesis that the within-class population
correlation coefficients are zero
to
test the hypothesis that the within-class population
correlation coefficients are zero
- Pooled Within-Class Correlation Coefficients and
to test the hypothesis that the partial
population correlation coefficients are zero
- Between-Class Correlation Coefficients and
to test the hypothesis that the between-class population
correlation coefficients are zero
- Total-Sample Correlation Coefficients and
to test the hypothesis that the total population
correlation coefficients are zero
- Simple descriptive Statistics including N (the number of
observations), Sum, Mean, Variance, and Standard Deviation
both for the total sample and within each class
- Total-Sample Standardized Class Means, obtained by
subtracting the grand mean from each class mean and
dividing by the total sample standard deviation
- Pooled Within-Class Standardized Class Means, obtained
by subtracting the grand mean from each class mean and
dividing by the pooled within-class standard deviation
- Pairwise Squared Distances Between Groups
- Univariate Test Statistics, including Total-Sample Standard Deviations,
Pooled Within-Class Standard Deviations, Between-Class Standard
Deviations, R2, R2/(1-R2), F, and Pr > F
(univariate F values and probability levels for one-way
analyses of variance)
- Multivariate Statistics and F Approximations, including
Wilks' Lambda, Pillai's Trace, Hotelling-Lawley Trace, and
Roy's Greatest Root with F approximations, degrees of
freedom (Num DF and Den DF), and probability values (Pr > F).
Each of these four multivariate statistics tests the
hypothesis that the class means are equal in the population.
See Chapter 3, "Introduction to Regression Procedures," for more information.
If you specify METHOD=NORMAL, the
following three statistics are displayed:
- Covariance Matrix Information, including Covariance
Matrix Rank and Natural Log of Determinant of the
Covariance Matrix for each group (POOL=TEST, POOL=NO)
and for the pooled within-group (POOL=TEST, POOL=YES)
- Optionally, Test of Homogeneity of Within Covariance
Matrices (the results of a chi-square test of homogeneity
of the within-group covariance matrices) (Morrison 1976;
Kendall, Stuart, and Ord 1983; Anderson 1984)
- Pairwise Generalized Squared Distances Between Groups
If the CANONICAL option is specified,
the displayed output contains these statistics:
- Canonical Correlations
- Adjusted Canonical Correlations (Lawley 1959).
These are asymptotically less biased than the raw
correlations and can be negative.
The adjusted canonical correlations may not be computable
and are displayed as missing values if two canonical
correlations are nearly equal or if some are close to zero.
A missing value is also displayed if an adjusted canonical
correlation is larger than a previous adjusted
canonical correlation.
- Approximate Standard Error of
the canonical correlations
- Squared Canonical Correlations
- Eigenvalues of E-1H.
Each eigenvalue is equal to
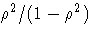 ,
where
,
where  is the corresponding squared canonical
correlation and can be interpreted as the ratio of
between-class variation to within-class variation for
the corresponding canonical variable.
The table includes Eigenvalues, Differences between
successive eigenvalues, the Proportion of the sum of
the eigenvalues, and the Cumulative proportion.
is the corresponding squared canonical
correlation and can be interpreted as the ratio of
between-class variation to within-class variation for
the corresponding canonical variable.
The table includes Eigenvalues, Differences between
successive eigenvalues, the Proportion of the sum of
the eigenvalues, and the Cumulative proportion.
- Likelihood Ratio for the hypothesis that the current
canonical correlation and all smaller ones are zero
in the population.
The likelihood ratio for all canonical
correlations equals Wilks' lambda.
- Approximate F statistic based on Rao's approximation to the
distribution of the likelihood ratio (Rao 1973, p. 556;
Kshirsagar 1972, p. 326)
- Num DF (numerator degrees of freedom), Den DF
(denominator degrees of freedom), and Pr > F,
the probability level associated with the F
statistic
The following statistic concerns the classification criterion:
- the Linear Discriminant Function, but only if you specify METHOD=NORMAL
and the pooled covariance matrix is used to calculate the
(generalized) squared distances
When the input DATA= data set is an ordinary SAS data set,
the displayed output includes the following:
- Optionally, the Resubstitution Results including Obs,
the observation number (if an ID statement is included,
the values of the ID variable are displayed instead of the
observation number), the actual group for the observation,
the group into which the developed criterion would classify
it, and the Posterior Probability of its Membership in
each group
- Resubstitution Summary, a summary of the performance of
the classification criterion based on resubstitution
classification results
- Error Count Estimate of the resubstitution
classification results
- Optionally, Posterior Probability Error Rate Estimates
of the resubstitution classification results
If you specify the CROSSVALIDATE option,
the displayed output contains these statistics:
- Optionally, the Cross-validation Results including Obs,
the observation number (if an ID statement is included,
the values of the ID variable are displayed instead of the
observation number), the actual group for the observation,
the group into which the developed criterion would classify
it, and the Posterior Probability of its Membership in
each group
- Cross-validation Summary, a summary of the performance of
the classification criterion based on cross validation
classification results
- Error Count Estimate of the cross validation
classification results
- Optionally, Posterior Probability Error Rate Estimates
of the cross validation classification results
If you specify the TESTDATA= option, the
displayed output contains these statistics:
- Optionally, the Classification Results including Obs,
the observation number (if a TESTID statement is included,
the values of the ID variable are displayed instead of the
observation number), the actual group for the observation
(if a TESTCLASS statement is included), the group into
which the developed criterion would classify it, and the
Posterior Probability of its Membership in each group
- Classification Summary, a summary of the
performance of the classification criterion
- Error Count Estimate of the test data classification results
- Optionally, Posterior Probability Error Rate Estimates
of the test data classification results
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.