MODEL Statement
- MODEL response < *censor ( list ) > = variables <
/options > ;
- MODEL (t1, t2) < *censor(list) > = variables <
/options > ;
The MODEL statement identifies the variables to be
used as the failure time variables,
the optional censoring variable, and the explanatory
variables. Two forms of MODEL syntax can be specified; the first form
allows one response variable, while the second form allows two variables
for the counting
process style of input (see the section "Counting Process Style of Input" for more information).
In the first MODEL statement, preceding the equal sign, is the name of
the failure time variable. This can optionally be followed
by an asterisk, the name of the censoring variable, and a
list of censoring values (separated by blanks or commas if there
is more than one) enclosed in parentheses. If the censoring variable
takes on one of these values, the corresponding failure time is
considered to be censored. The variables following the equal sign are
the explanatory variables (sometimes called independent
variables or covariates) for the model.
Instead of a single failure time variable, the second MODEL statement
identifies a pair of failure time variables.
Their names are enclosed in parentheses, and they signify the endpoints
of a semi-closed interval (t1,t2] during which the subject is at risk.
If the censoring variable takes on one of the censoring values,
the time t2 is considered to be censored.
The censoring variable and the explanatory variables must be numeric.
The failure time variables must contain nonnegative values.
Any observation with a negative failure time is excluded from the
analysis,
as is any observation with a missing value for any of the variables
listed in the MODEL statement.
You can specify the following options in the MODEL statement.
Ties-Handling Option
- TIES=method
-
specifies how to handle ties in the failure time. The TIES=
option can take the following values:
- BRESLOW
- uses the approximate likelihood of Breslow (1974).
This is the default value.
- DISCRETE
-
replaces the proportional hazards model
by the discrete logistic model
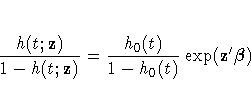
where h0(t) and
h(t;z) are discrete hazard functions.
- EFRON
- uses the approximate likelihood of Efron (1977).
- EXACT
-
computes the exact conditional probability under the proportional
hazards assumption that all tied event times occur
before censored times of the same value or before larger values.
This is equivalent to summing all terms of the marginal likelihood
for
 that are consistent with the observed data
(Kalbfleisch and Prentice 1980; DeLong, Guirguis, and So 1994).
that are consistent with the observed data
(Kalbfleisch and Prentice 1980; DeLong, Guirguis, and So 1994).
The EXACT method may take a considerable amount of computer
resources.
If ties are not extensive, the EFRON and BRESLOW methods provide
satisfactory approximations to the EXACT method for the continuous
time-scale model.
In general, Efron's approximation gives results that are much
closer to the EXACT method results than Breslow's approximation does.
If the time scale is genuinely discrete, you should use
the DISCRETE method. The DISCRETE method is also required in
the analysis of case-control studies when there is more than
one case in a matched set.
If there are no ties, all four methods result in the same
likelihood and yield identical estimates.
The default, TIES=BRESLOW, is the most efficient method
when there are no ties.
Model-Specification Options
- ENTRYTIME=variable
- ENTRY=variable
-
specifies the name of the variable that represents the left truncation
time. This option has no effect when the counting process style of
input is specified.
See
the section "Left Truncation of Failure Times" for more information.
- NOFIT
-
performs the global score test,
which tests the joint
significance of all the explanatory variables in
the MODEL statement. No parameters are estimated.
If the NOFIT option is specified along with other MODEL statement
options, NOFIT takes precedence, and all other options
are ignored except the TIES= option.
- OFFSET=name
-
specifies the name of an offset
variable, which is an explanatory variable with a
regression coefficient fixed as one. This option
can be used to incorporate risk weights for the likelihood function.
- SELECTION=method
-
specifies the method used to select the model. The methods
available are
- BACKWARD | B
- requests backward elimination.
- FORWARD | F
- requests forward selection.
- NONE | N
- fits the complete model specified in the
MODEL statement. This is the default value.
- SCORE
- requests best subset selection. It identifies
a specified number of models
with the highest score
chi-squared statistic for all possible model sizes
ranging from one explanatory variable to the total number of
explanatory variables listed in the MODEL statement.
- STEPWISE | S
- requests stepwise selection.
For more information, see the section "Variable Selection Methods".
Model-Building Options
The following options enable you to provide additional specifications
for the
BACKWARD, FORWARD, SCORE, and STEPWISE
model selection methods. They have no effect
when SELECTION=NONE.
Only the INCLUDE=, START=, STOP=, and BEST= options work with
the SCORE method.
- BEST=n
-
is used exclusively with the SCORE model selection method.
The BEST=n option specifies that n models with the highest
score chi-squared statistics are
to be displayed for each model size. If the option is omitted
and there are no more than ten explanatory variables, then all
possible models are listed for each model size.
If the option is omitted and there are more than ten
explanatory variables, then the number of models selected for
each model size is, at most, equal to the number of
explanatory variables listed in the MODEL statement.
See Example 49.2 for an illustration
of the SCORE selection method and the BEST= option.
- DETAILS
-
produces a detailed display at each step of the model-building
process. It produces an "Analysis of Variables Not in the
Model" table before displaying the variable selected for entry
for FORWARD or STEPWISE selection.
For each model fitted, it produces
the "Analysis of Maximum Likelihood Estimates" table.
See Example 49.1 for a discussion of these tables.
- INCLUDE=n
-
includes the first n explanatory variables listed in the MODEL
statement in every model. The value for n ranges from
1 to s, where s is the number of explanatory
variables in the MODEL statement. The default value of n is 0.
- MAXSTEP=n
-
specifies the maximum number of times the explanatory
variables can move in and out of the model before the
STEPWISE model-building process ends.
The default value for n
is twice the number of explanatory variables in the MODEL statement.
The option has no effect for other model selection methods.
- SEQUENTIAL
-
forces variables to be added to the model in the order
specified in the MODEL statement or to be eliminated from the
model in the reverse order specified in the MODEL statement.
- SLENTRY=value
- SLE=value
-
specifies the significance level
(a value between
0 and 1) for entering an explanatory variable into the model
in the FORWARD or STEPWISE method. For all variables
not in the model, the one with the smallest p-value is entered
if the p-value is less than or equal to the specified significance
level. The default value is 0.05.
- SLSTAY=value
-
- SLS=value
-
specifies the significance level
(a value between
0 and 1) for removing an explanatory variable from the model
in the BACKWARD or STEPWISE method.
For all variables
in the model, the one with the largest
p-value is removed if the p-value exceeds the
specified significance level. The default value is
0.05.
- START=n
-
begins the FORWARD, BACKWARD, or STEPWISE model selection
process with the first n explanatory
variables listed in the MODEL statement. The value for n ranges
from 0 to s, where s is the total number of explanatory
variables in the MODEL statement. The default value of n is
s for the BACKWARD method and 0 for the FORWARD and STEPWISE
methods. Note that START=n specifies only that the first
n explanatory variables appear in the first model, while
INCLUDE=n specifies that the first n explanatory variables
be included in every model.
For the SCORE method, START=n specifies that the smallest
models contain n explanatory variables, where n ranges
from 1 to s. The default value of n is 1.
- STOP=n
-
specifies the maximum (FORWARD method) or minimum
(BACKWARD method) number of explanatory variables to
be included in the final model. The value for n ranges from
0 to s, where
s is the number of explanatory variables in the MODEL
statement. The default value of n is 0 for the BACKWARD method
and s for the FORWARD method.
For the SCORE method, STOP=n specifies that the largest
models contain n explanatory variables, where n ranges
from 1 to s. The default value of n is s.
The STOP= option has no effect for the STEPWISE method.
- STOPRES
-
- SR
- specifies that the addition and deletion of variables
are to be based on the result
of the likelihood score test
for testing the joint
significance of variables not in the model.
This score chi-squared statistic is
referred to as the
residual chi-square.
In the FORWARD method,
the STOPRES option enters the explanatory variables into the model one
at a time until the residual chi-square becomes insignificant
(that is, until the p-value of the residual chi-square
exceeds
the SLENTRY= value). In the BACKWARD method, the STOPRES option
removes variables from the model one at a time until the
residual chi-square becomes significant (that is, until the
p-value of the residual chi-square becomes less than the
SLSTAY= value). The STOPRES option has no effect for the
STEPWISE method.
Optimization Options
Four convergence criteria are allowed: ABSFCONV=, FCONV=, GCONV=,
and XCONV=.
If you specify more than one
convergence criterion, the optimization is terminated as soon as one
of the criteria is satisfied. If none of the criteria is specified, the
default is GCONV=1E-8.
- ABSFCONV=value
- specifies the absolute function convergence criterion. Termination
requires a small change in the objective
function (log partial likelihood function) in
subsequent iterations,
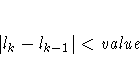
where lk is the value of the objective function
at iteration k.
- CONVERGELIKE=value
- is the same as specifying the ABSFCONV= option.
- CONVERGEPARM=value
- is the same as specifying the XCONV= option.
- FCONV=value
- specifies the relative function convergence criterion. Termination
requires a small relative change in the objective
function (log partial likelihood function) in
subsequent iterations,
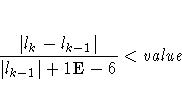
where lk is the value of the objective function at
iteration k.
- GCONV=value
- specifies the relative gradient convergence criterion. Termination
requires that the normalized prediction function reduction is small,
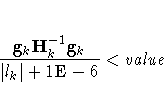
where lk is the log partial likelihood,
gk is the gradient vector (first partial
derivatives of the log partial likelihood), and Hk is
the negative Hessian matrix (second partial derivatives of
the log partial likelihood), all at iteration k.
- MAXITER=n
-
specifies the maximum number of iterations allowed.
The default value for n is 25.
If convergence is not attained in n iterations, the displayed
output and all data sets created by PROC PHREG contain results that
are based on the last maximum likelihood iteration.
- RIDGING=ABSOLUTE | RELATIVE | NONE
- specifies the technique to improve the log-likelihood when its value is
worse than that of the previous step.
For RIDGING=ABSOLUTE, the diagonal elements
of the negative (expected) Hessian are inflated by adding the ridge value.
For RIDGING=RELATIVE, the diagonal elements are inflated by the factor
equal to 1 plus the ridge value. For RIDGING=NONE, the crude line-search
method of taking half a step is used instead of ridging.
- SINGULAR=value
-
specifies the singularity criterion
for determining linear
dependencies in the set of explanatory variables. The
default value is 10-12.
- XCONV=value
- specifies the relative parameter convergence criterion. Termination
requires a small relative parameter change in subsequent iterations,
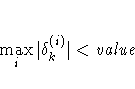
where
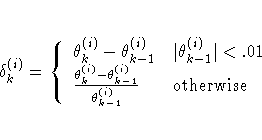
where  is the estimate of the ith parameter at iteration
k.
is the estimate of the ith parameter at iteration
k.
Display Options
- ALPHA=value
-
sets the significance level
used for the confidence limits for the
hazards ratios.
The value must be between 0 and 1. The
default value is
0.05, which results in the calculation of a 95% confidence
interval. This option has no effect unless the RISKLIMITS
option is specified.
- CORRB
-
displays the estimated correlation matrix of the parameter
estimates.
- COVB
-
displays the estimated covariance matrix of the parameter
estimates.
- ITPRINT
-
displays the iteration history, including the last evaluation of
the gradient vector.
- RISKLIMITS
-
- RL
- displays, for each explanatory variable, the
 confidence limits for the hazards ratio (
confidence limits for the hazards ratio ( ).
The value for
).
The value for  is determined by the ALPHA= option.
is determined by the ALPHA= option.
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.