![]()
- A good plot to look at here is a Q-Q plot in which the 16 numbers,
sorted into order from smallest to largest,
are plotted against the 16 z values which split the area under the
normal curve into 17 equal pieces. Since 1/17 = 0.0588 the first such
value is -1.565. Similarly, 2/17 = 0.118 is the area to the left of -1.18
and the second smallest value would be plotted against this.
I did not talk about this in class so all you could really do is look for obvious outliers or asymmetry. I see no sign of any problem.
- I get
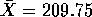 and s = 24.16. The t multiplier
on 15 degrees of freedom is 2.13 so the interval is
and s = 24.16. The t multiplier
on 15 degrees of freedom is 2.13 so the interval is
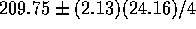 .
.
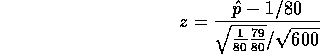
where ![]() . Thus z = 1.65, P=0.10 and the test
rejects at the 20% level but not at the 5% level. In part a) the
type of error you might be making is type II, incorrectly accepting the
null (because you do accept the null in a).
. Thus z = 1.65, P=0.10 and the test
rejects at the 20% level but not at the 5% level. In part a) the
type of error you might be making is type II, incorrectly accepting the
null (because you do accept the null in a).
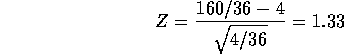
which leads to a P-value of 9.18% which I would describe as some,
weak, evidence against the null hypothesis and in favour of the assertion
that ![]() .
.
- You are asked to compute P(a < U < b ) where
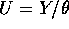 ,
,
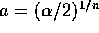 and
and 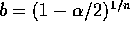 . The definition
of density means that this is
. The definition
of density means that this is
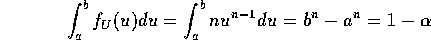
Now solve
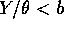 to get
to get 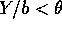 and similarly for a.
and similarly for a. - If
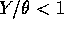 then
then 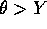 and if
and if 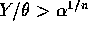 then
then 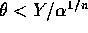 . The probability
of this event is just as in a) but with the limits a and b changed
to
. The probability
of this event is just as in a) but with the limits a and b changed
to 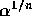 and 1 so the probability is
and 1 so the probability is 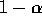 and the
interval runs from Y to
and the
interval runs from Y to 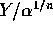 .
. - The length of the two intervals is Y times (1/a -1/b) which
is shorter in the case of b) (For instance in the example with
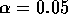 and n = 5 we find the interval in a) has length 4.56 while that
in b has length 3.45.) For the data in hand Y = 4.2, and
the limits in b) are 4.2 to 7.65.
and n = 5 we find the interval in a) has length 4.56 while that
in b has length 3.45.) For the data in hand Y = 4.2, and
the limits in b) are 4.2 to 7.65.
I remark that this model assumes that the buses always run exactly
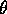 minutes apart and the writer arrives at a ``random time'' -- not very realistic.
minutes apart and the writer arrives at a ``random time'' -- not very realistic.