~lockhart/Teaching/Courses/802/Data/Asst3Q1The first 6 are Rocky Mountain males, then 3 females then 10 Arctic males and 6 Arctic females. The 9 variables are 9 different lengths measured on the skulls of the animals (in millimetres).
- Use pairwise
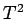 tests to decide if any of the pairs are
indistinguishable on the basis of the data here.
tests to decide if any of the pairs are
indistinguishable on the basis of the data here.
- Assess whether there are any variables on which all 4 groups have
means so similar that the variable in question will not really help
discriminate. A hypothesis test with a large
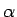 is probably useful.
is probably useful.
- For the standard linear discriminant rule classify all of the data points and determine the raw and cross-validated error rates.
R: Classify a newWe want to estimate the error rates for this classifier. The usual linear rule for known parameters would classifyas coming from population 2 if
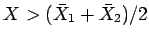
where
NOTE: if
- Derive an expression for the conditional error rates given
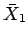 and
and 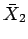 of rule R as a function
of , ,
of rule R as a function
of , , 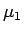 and
and 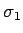 .
.
- Find a Taylor expansion for these quantities as a function of
and about the points and
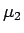 . Keep
terms out to quadratic in
. Keep
terms out to quadratic in
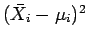 .
.
- Use this expression to compute the expected error rate and show that
it is the error rate
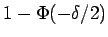 for the linear classifier
given above plus a term of the
form
for the linear classifier
given above plus a term of the
form
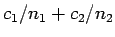 . Your answer should include a formula for the
. Your answer should include a formula for the 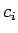 .
.
- The cross validation estimate of this error rate is

Use the result in the first 3 parts of this question but with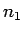 1 smaller get a formula for the expected value of this
estimate plus terms like
1 smaller get a formula for the expected value of this
estimate plus terms like
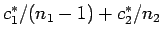 .
.
- Put these results together to argue that the
expected value of the cross validation estimate of the error rates is
the same, to terms of order
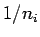 as the expected error rate.
as the expected error rate.