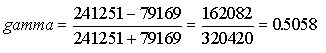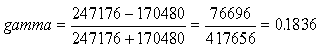1. What does it mean to say that a measure has a PRE interpretation?
It means that the measure can be interpreted in a way that tells you the percentage reduction in errors you would make when predicting the value of one variable based on the value of the other variable, expressed as a proportion of how many you would have made if you only had information about one variable.
2. In a relationship between an ordinal-scale variable and a nominal-scale variable, which measures of association are appropriate?
Gamma, Somers' d, or Spearman's rho can be used with this type of data. You can also use lambda, but it is blind to the additional information that is contained in ordinal-scaled data and not in nominal-scaled data. Because of this weakness, lambda is likely to underestimate the strength of the relationship.
3. What does it mean to say that the association between one pair of nominal-scale variables is stronger than the association between another pair of nominal-scale variables?
With nominal data, measures of the strength of association are based on your ability to correctly guess or predict the value of one variable when you know the value of the other one. The only thing considered here is whether your guess is correct or incorrect; direction or size of errors are not meaningful for nominal data. If the association between the first pair is stronger than the association between the second pair, you can do a better job of guessing or predicting the value of one variable when you know the value of the other one for the first pair than you can with the second pair.
4.In a relationship between an interval-scale variable and a nominal-scale variable, which measures of association are appropriate?
As is the case with univariate measures of central tendency and dispersion, any measure that can be used with one of the lower levels of scaling can also be used with the higher ones. This means that you can use lambda and Yule's Q for ordinal and interval data and gamma or Somers' d for interval or ratio data, although you may have to reduce the number of categories in the ordinal data or convert the continuous interval data to discrete categorical data. Since this conversion from higher to lower levels of scaling requires you to throw away some of the information originally contained in the data, you will probably prefer to use the stronger measures instead.
5.In a relationship between an interval-scale variable and an ordinal-scale variable, which measures of association are appropriate?
As is the case with univariate measures of central tendency and dispersion, any measure that can be used with one of the lower levels of scaling can also be used with the higher ones. See the answer to question 4 for more information.
6.For data in which you could use either lambda or gamma, why are you likely to get a higher result with gamma?
Gamma uses more of the information in the data than lambda does. Lambda works mainly with the modal values in rows (or columns) and is "blind" to much of the information contained in the data. Gamma, on the other hand, uses information about the relative ordinal positions of all the values in the data matrix. It is thus able to "see" more of the relationship between the variables.
Calculate lambda and Yule's Q for the data in this table:
| Support for proposed Free Beer Law by Age, Texas, 1995 | ||||
| Age | ||||
|
|
Over 21 | Under 21 |
|
|
|
|
|
|||
|
Favor
|
|
371 | 663 | 1034 |
|
Oppose
|
|
218 | 178 | 396 |
|
Total
|
589 | 841 | 1430 | |
Lambda:
The marginal modal value for the dependent variable ("Support") rows is "Favor" with 1034 cases, so you would guess "Favor" all the time. You would make 396 errors if this is all the information you had.Now you take the second variable into consideration. For respondents in the "Over 21" column, you would guess "Favor" because more people (371) are in the "Favor" row than in the "Oppose" row (218). You would make 218 errors here. For respondents in the "Under 21" column, you would guess "Favor" because more people (663) are in the "Favor" row than in the "Oppose" row (178). You would make 178 errors here. The total number of errors would be 396, which happens to be the exact same as the number based only on the dependent variable.
To calculate lambda, you divide the difference between the number of errors based on the dependent variable and the number of errors based on both variables by the number of errors based on the dependent variable. In this case you divide (396 - 396 ) by 396 to get 0÷396 = 0.
Gamma:
To get the number of pairs having the same direction of ranking on the two variables, multiply the frequency of each cell by the sum of the frequencies of all cells below and to the right of it in the table. Add up all these products. For this table you would get: 371× 178 = 66038
To get the number of discordant pairs, multiply the frequency of each cell by the sum of the frequencies of all cells appearing below and to the left of it in the table. Add all these products together. For this table you would get: 663 × 218 = 144534.Now put these numbers into the equation for gamma:

There is a moderately negative relation between age and support for the free beer law. If you know whether or not someone supports the proposed law, you can make about 37% fewer errors than when your guess of the person's age is based only on the total number of younger and older people in the sample.
7.Why does lambda give you different results when you starting with the second variable than with the first? Explain what the cause of the difference is and what it means.
If you start with the independent variable instead of the dependent variable, you get different results. The marginal modal value for the independent variable ("Age") rows is "Under 21" with 841 cases, so you would always guess "Under 21". You would make 589 errors if this is all the information you had.
Now you take the second variable into consideration. For respondents in the "Favor" row, you would guess "Under 21" because more people (663) are in the "Under 21" column than in the "Over 21" column (371). You would make 371 errors here. For respondents in the "Oppose" row, you would guess "Over 21" because more people (218) are in the "Over 21" column than in the "Under 21" column (178). You would make 178 errors here. The total number of errors would be 371 + 178 = 549, which is less than 589 -- the number based only on the independent variable.
To calculate lambda, you divide the difference between the number of errors based on the independent variable and the number of errors based on both variables by the number of errors based on the independent variable. In this case you divide (589 - 371 ) by 589 to get 218÷589 = 0.3701.
The difference is due to the fact that the majority of people in both age groups were in favor of the proposed law, while the majority of those in favor were under 21 and the majority opposed were over 21. Because of this difference, you make fewer errors when you use the support variable to predict the age than when you use the age variable to predict the level of support for the proposed law.
8.Discuss what the two measures tell you about the relationship between Age and Support for the proposed law.
While the majority of people in both age groups are in favor of the proposed law, the majority of those in favor are under 21 and the majority opposed are over 21.
9. Calculate lambda and Yule's Q for the data in the following tables.
| Support for proposed Free Beer Law by Education, Texas, 1995 | |||||
| Education | |||||
|
|
less than High School | High School | Some college or more | Total | |
|
Favor
|
|
427 | 258 | 169 | 854 |
|
Oppose
|
|
111 | 188 | 235 | 434 |
|
Total
|
538 | 446 | 404 | 1288 | |
Lambda:
The dependent variable is Support. Using only that variable, you would always predict "Favor" because more people fall in this row (854) than in the "Oppose" row (434). With this strategy, you would make 434 errors.
When you also use the independent variable, you would guess "Favor" for people with less than high school and make 111 errors; you would guess "Favor" for people who completed high school and make 188 errors; and you would guess "Oppose" for people with some college or more and make 169 errors. The total number of errors with this strategy would be 111 + 188 + 169 = 468, which is 34 more than with the other strategy (434). The value of lambda would be the difference divided by the original number of errors, or 34 ÷ 434 = 0.078.
It is not possible to calculate Yule's Q for these tables because it only works for dichotomous variables. The education variable is not dichotomous, and it happens to be ordinal, which is good because it is possible to use gamma which requires ordinal data.
Gamma
Gamma uses this formula:
To get the number of pairs having the same direction of ranking on the two variables, multiply the frequency of each cell by the sum of the frequencies of all cells below and to the right of it in the table. Add up all these products. For the first table above you would get:

To get the number of discordant pairs, multiply the frequency of each cell by the sum of the frequencies of all cells appearing below and to the left of it in the table. Add all these products together. For this table you would get:
Now subtract the number of discordant pairs from the number of concordant pairs and divide the result by the sum of the number of concordant and discordant pairs:
Gamma for this table shows that there is a moderately strong relationship between the two variables: the more education the person has, the more likely it is that the person will oppose the proposed law.
| Support for proposed Free Beer Law by Education, Alberta, 1995 | |||||
| Education | |||||
|
|
less than High School | High School | Some college or more | Total | |
| Favor | (+) | 282 | 238 | 278 | 798 |
| Oppose | (-) | 186 | 268 | 330 | 784 |
| Total | 468 | 506 | 608 | 1582 | |
Lambda:
The dependent variable is Support. Using only that variable, you would always predict "Favor" because more people fall in this row (798) than in the "Oppose" row (784). With this strategy, you would make 784 errors.
When you also use the independent variable, you would guess "Favor" for people with less than high school and make 186 errors; you would guess "Oppose" for people who completed high school and make 238 errors; and you would guess "Oppose" for people with some college or more and make 278 errors. The total number of errors with this strategy would be 186 + 238 + 278 = 702, which is 82 fewer than with the other strategy (784). The value of lambda would be the difference divided by the original number of errors, or 82 ÷ 784 = 0.1046.
Gamma
The gamma value for the Alberta table, calculated as shown here:
is smaller than the gamma for the Texas table (0.5058).
10. Discuss what the two measures tell you about the relationship between Age and Support for the proposed law in Texas and in Alberta.
It seems to be the case that the relation between level of education and support for the free beer law is much stronger in Texas than it is in Alberta. This is not shown by lambda ( 0.078 vs 0.1046),which is unable to take advantage of the additional information available in the ordinal variable, but it is clearly shown by gamma which does use the extra information (0.5058 for Texas vs. 0.1836 for Alberta).