Language for Communication¶
before the rise in popularity of statistical language techniques, many researchers thought that techniques related to grammar and semantics was a going to be a more fruitful avenue of research
for now, statistical techniques tend to be more useful, but for some complex problems it seems that deeper linguistic knowledge is necessary
Grammars¶
we all know that words fall into different part of speech categories, or syntactic categories
e.g. apple, cat, house, sky are all nouns
e.g. run, jump, talk, think, sleep are all verbs
e.g. red, heavy, loud, awful all adjectives
in grammatical natural language, sequences of words can be grouped by their syntactic categories into phrase structures, which can then also be grouped into phrase structures
- thus, we can describe the syntax of natural using a syntax tree
a grammar is a set of rules that describes the allowable word strings in a language
for example, a simple grammar rule might look like this:
VP -> Verb
| VP NP
this is one grammar rule: VP stands for verb phrase, NP stands for
noun phrase, and Verb stands for a word that is a verb
| means “or”
the VP on the left of the -> arrow is is the head of the rule and
on the right side is what the VP can expand into, i.e. a verb phrase is
either a verb, or a verb phrase followed by a noun phrase
e.g. the verb phrase “eat the apple” consists of the verb eat and the noun phrase the apple
symbols such as VP and NP are called non-terminal symbols because
they appear as the head of one or more rules
symbols like Verb, that don’t appear as the head of any rules, are called
terminal symbols
probabilistic grammars are a popular modification of basic grammars that add a probability to each case of a grammar rule
- VP -> Verb [0.70]
you might get the probabilities from looking at a database of documents and
counting how frequently a verb phrase is a verb, or when it’s a VP NP
in practice, it is quite difficult to come up with good grammars for natural languages (such as English)
- in part this is because no two people would agree on all the grammar rules
but it is often possible to make useful grammars for restricted subsets of natural language
- but even then it can be quite tricky to create grammars by hand, and so grammars are often created using machine learning
the textbook introduces a simple English-like language called \(\varepsilon_0\)
\(\varepsilon_0\) it consists of
- a lexicon, i.e. a list of legal words in the language
- a set of phrase grammars rules that describe the legal sequences of words



the grammar can generate sentences like
- John is in the pit.
- The wumpus that stinks is in 2 2.
- Mary is in Boston and the wumpus is in 3 2.
\(\varepsilon_0\) is not perfect though
- it overgenerates, i.e. it allows ungrammatical sentences like “Me go Boston”
- it also undergenerates, i.e. it cannot generate the sentence “I think the wumpus is smelly.”
Parsing: Syntactic Analysis¶
parsing is the problem of converting a string of words to uncover its phrase structure
- this usually means using a grammar to convert a string into a parse tree tree that shows the part of speech of each segment of words from the input string
there are two basic parsing strategies: top-down parsing and bottom-up parsing
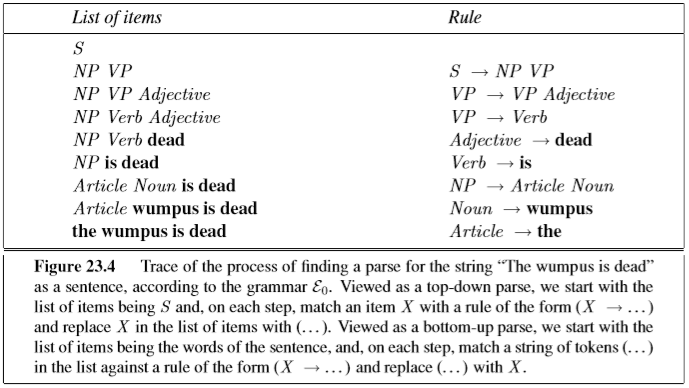
both approaches to parsing can be inefficient on certain sentences, e.g. these two sentences
Have the students in section 2 of CMPT 125 take the exam.
Have the students in section 2 of CMPT 125 taken the exam.
a parsing algorithm that looks at words in left-to-right order won’t know the phrase structure of the first part of either sentence until it gets to take or taken
- so the algorithm would have to guess the part of speech of the initial phrase is, and, if it guesses wrong, it would have to backtrack to the start of the sentence to re-parse it using a different choice of phrase for the first part
- in general, parsing is a difficult and complex problem because of issues like this!
to speed up parsing, dynamic programming can be used to store the phrase structure of sub-segments of the string being analyzed
- e.g. once an algorithm discovers that the phrase “the students in section 2 of CMPT 125” is an NP (noun phrase), it can store that information so it doesn’t need to be re-computed if backtracking is needed
- the data structure for storing this information is often called a chart, and so parsing algorithms that use this trick are sometimes called chart parsers
for example, the CYK algorithm is a bottom-up chart parser that runs in \(O(mn^3)\) time on an input string consisting of \(n\) words and \(m\) is the size of the lexicon
- \(O(mn^3)\) is quite efficient for a general-purpose parser, although for restricted parsing problems there are algorithms that can run faster
- however, it requires that the grammar first be converted to a special format called Chomsky normal form
it’s quite possible that some sentences could have more than one parse, e.g.:
Fall leaves fall and spring leaves spring.
all the words except “and” in this sentence could be a verb or a noun, and so multiple parses are possible, e.g. there are four parses in \(\varepsilon_0\):

usually we are only interested in the top one or few parses of a sentence (i.e. based on rule probabilities), and the CYK algorithm doesn’t get all parses unless we ask for them
it is possible to learn probabilistic grammars:
- if you happen to have a large collection of parsed sentences, you can use basic counting to estimate rules and their probabilities
- if you only have a large collection of raw sentences that are unparsed, it is possible but more difficult to learn a grammar; see the text if you are curious about some of the details
Complexities of Parsing¶
natural languages are extremely complex, and here we point out a few of those complexities
time and tense, e.g.
- Abby kicked the ball.
- Abby kicks the ball.
- Abby is kicking the ball.
- Abby was kicking the ball.
- Abby will kick the ball.
- Abby will have kicked the ball.
the notion time is important in language, and it can be modelled logically, e.g. by using logic to specify points, or extends, of time
quantification, e.g.
- Everybody loves a parade.
this could mean “for every person X, there is parade P that X loves”
or it could mean “there is a parade P, such that for every person X, X loves P”
- The horse is beautiful.
does this mean “a particular horse (maybe named Man’O War) is beautiful”?
or does it mean “all horses are beautiful”?
you may personally have a preferred interpretation, but both interpretations are at least possible and may need to be considered when reading such a sentence
pragmatics, e.g.
- I am in Boston tomorrow.
the words “I” and “tomorrow” are referring to things outside of the sentence, so this sentence can only be understood in context
- It sure is cold in here.
on the surface, this sentence appears to be an assertion that it is cold; but in the some situations, it might actually be a request to someone that they close the window
- this is an example of a speech act, i.e. the intention of saying “It sure is cold in here” is to achieve the effect of having the window closed
- of course, someone could just say “Could you please close the window?”, but people don’t always use direct language
ambiguity, e.g.
- We’re going to cut the homeless in half by 2025.
- Include your children when baking cookies.
- Milk drinkers are turning to powder.
these sentences are clearly ambiguous to most native English speakers, and it most cases there is a clear preferred interpretation
but research into parsing with computers has shown that almost all utterances are highly ambiguous, but in most cases native speakers have clear preferred interpretations that make them seem non-ambiguous
- parsing systems with large lexicons can discover sentence with thousands of interpretations
individual words can have many different meanings, e.g. back can be
- an adverb (“go back!”)
- an adjective (“the back door”)
- a noun (“it’s in the back”)
- a verb (“back up!”)
there can also be non-literal language, e.g.
- SFU announced a new school of Machine Learning
this does not mean SFU can talk
- My car drinks gasoline like crazy.
this does not mean that cars drink gasoline!
Machine Translation¶
machine translation is the problem of getting a computer to automatically translate from one language to another without requiring a human
this is a huge topic in AI, since it clearly has many uses
a lot of NLP work has been inspired by, or done in service to, the problem of machine translation