GRASS: A new learning algorithm for 3D content creation to be featured at SIGGRAPH 2017
This is a guest article written by Dr. Richard (Hao) Zhang, who is a professor in the School of Computing Science.
3D modeling has become a common part of our everyday lives. Digital 3D models making up virtual scenes have become indispensible for filmmakers to create surreal visual effects, game developers to enrich player experience, architects and designers to explore new designs, and scientists to visualize molecular structures and interactions. With the rapid advances of VR/AR and 3D printing technologies, the demand for 3D modeling has increased tremendously in recent years. However, if you have ever tried to build a 3D model using commercial software such as Maya, you know that it is a lengthy and laborious process best left for professionals. A focus of my research team has been to enable novice users to easily and quickly create 3D models.
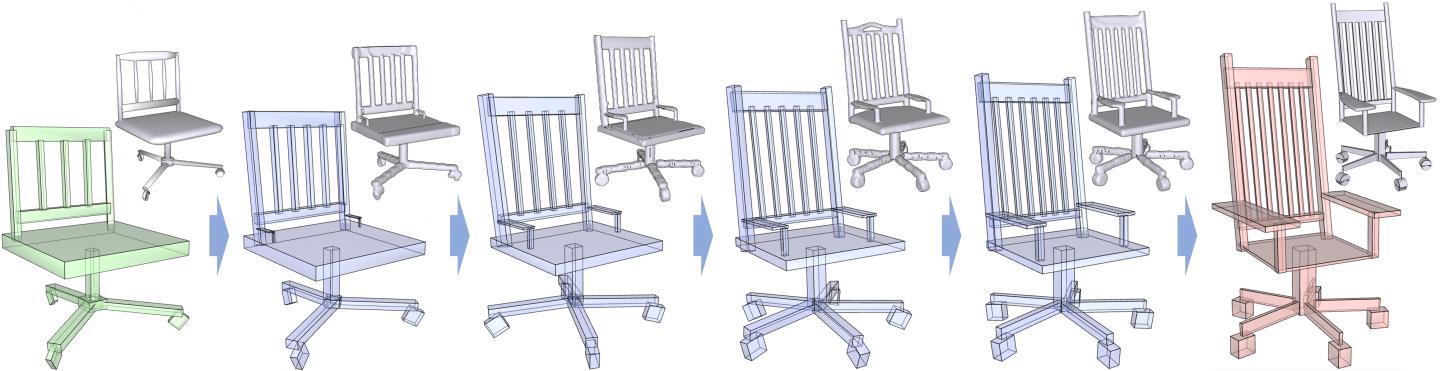
In our latest work, Generative Recursive Autoencoders for Shape Structures, or GRASS, we develop an algorithm to learn structural representations of 3D shapes and then apply the learned representations to generate 3D objects in a variety of ways and fully automatically. With traditional modeling, in order to create a 3D model of a chair, one needs to build shapes for the backrest, seat, legs, and armrests individually, and then compose them in a structurally valid way. Building many variations of 3D chairs with different styles is clearly a tedious process. With GRASS, a novel 3D chair could be generated automatically from a randomly sampled code, which serves as the DNA for 3D shapes. To have better control in the modeling, a series of 3D chairs can be generated as in-betweens, transforming from a source and target, which may differ both in shape and in their part structures, as shown in the figure.
The original motivation for developing GRASS can be traced back to 2012, when we published a SIGGRAPH paper on evolving a set of 3D shapes to generate fit and diverse offsprings. Even then we asked ourselves what would be the appropriate (shape) DNA to encode and generate 3D shapes.
Kai Xu, a visiting PhD student from China working under my supervision at SFU at the time, was the lead student on that project. We teamed up again on GRASS and collaborated with researchers from Adobe Research, IIT, and Stanford University.
Learning generative models for 3D shapes is a hotly pursued problem in computer graphics, computer vision, and machine learning. GRASS makes use of a lesser-known machine learning technique called Recursive Neural Network. Not to be confused with Recurrent Neural Network (RNN), which is much better known.
Recursive neural networks can be trained to learn tree representations, e.g., of natural languages or image contents. Combined with another machine learning technique called autoencoders, GRASS is able to take a structural representation of a 3D shape, which is a tree of shape parts organized in a particular way, transform it into a code and then decode the code back into a tree. The decoder serves as the 3D shape generator and the generative codes can be produced in several different ways.
The particular tree representation for 3D shapes adopted by GRASS was from our earlier work in 2011, when we handcrafted a set of rules to define how to best represent shape structures using a tree. Now in 2017, we have a machine to learn such a representation just by showing it many examples.
I am amazed by how machine learning has quickly taken a strong hold in the field of computer graphics.
What sets GRASS apart from all other deep neural networks for 3D shape encoding and generation is its focus on learning structural representations. Our view is that a 3D object is best understood as a functionally meaningful assembly of its parts, not as a set of photographs, depth scans, or a voxel grid (a voxel to a 3D shape is like a pixel in a digital image). This distinction allows GRASS to generate novel shape structures and clean 3D shapes, since we first generate just bounding boxes of shape parts and then fill in the part geometries in each box.
We are still far from finding true shape DNAs though. The codes learned by GRASS are not yet readable and we cannot perform mutations or crossovers over them, like real DNA. We are working on it now and there is still a lot to do!
Zhang and his team will be presenting this research at SIGGRAPH 2017 in Los Angeles. The premier annual conference featuring the latest research and innovations in computer graphics and interactive techniques runs from July 30 to August 3. GRASS is one of the only six papers selected by SIGGRAPH for a press release this year, which can be found here.
Below is a list of SFU researchers whose work will be featured at SIGGRAPH 2017:
Comparing 3D Shapes and Parts
July 31, 3:45 p.m. - 5:45 p.m.
Three papers in this session featuring SFU researchers: Hao Zhang, Chenyang Zhu, Renjiao Yi, Wallace Lira, Ibraheem Alhashim
Video
August 3, 9:00 a.m – 10:30 a.m.
SFU researchers: Ping Tan, Zhaopeng Cui
Human Motion
August 3, 10:45 a.m. – 11:55 a.m.
SFU researcher: Eugene Fiume