Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| Language Reference |
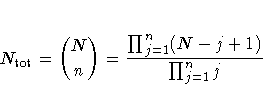
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Nlower | 500 | 50 | 22 | 17 | 15 | 14 | 0 | 0 | 0 | 0 |
| Nupper | 1000000 | 1414 | 182 | 71 | 43 | 32 | 27 | 24 | 23 | 22 |
| NRep | 500 | 1000 | 1500 | 2000 | 2500 | 3000 | 3000 | 3000 | 3000 | 3000 |
| n | 11 | 12 | 13 | 14 | 15 |
| Nlower | 0 | 0 | 0 | 0 | 0 |
| Nupper | 22 | 22 | 22 | 23 | 23 |
| NRep | 3000 | 3000 | 3000 | 3000 | 3000 |
print "Stackloss Data";
aa = { 1 80 27 89 42,
1 80 27 88 37,
1 75 25 90 37,
1 62 24 87 28,
1 62 22 87 18,
1 62 23 87 18,
1 62 24 93 19,
1 62 24 93 20,
1 58 23 87 15,
1 58 18 80 14,
1 58 18 89 14,
1 58 17 88 13,
1 58 18 82 11,
1 58 19 93 12,
1 50 18 89 8,
1 50 18 86 7,
1 50 19 72 8,
1 50 19 79 8,
1 50 20 80 9,
1 56 20 82 15,
1 70 20 91 15 };
Rousseeuw & Leroy (1987, p.76) cite a large number of papers where this data set was analyzed before and state that most researchers "concluded that observations 1, 3, 4, and 21 were outliers," and some people also reported observation 2 as outlier.
For N=21 and n=4 (three explanatory variables including intercept), you obtain a total of 5985 different subsets of 4 observations out of 21. If you decide not to specify optn[5], your LMS and LTS algorithms draw Nrep=2000 random sample subsets. Since there is a large number of subsets with singular linear systems, which you do not want to print, you chose optn[2]=2; for reduced printed output.
a = aa[,2:4]; b = aa[,5]; optn = j(8,1,.); optn[2]= 2; /* ipri */ optn[3]= 3; /* ilsq */ optn[8]= 3; /* icov */ CALL LMS(sc,coef,wgt,optn,b,a);
LMS: The 13th ordered squared residual will be minimized.
Median and Mean
Median Mean
VAR1 58 60.428571429
VAR2 20 21.095238095
VAR3 87 86.285714286
Intercep 1 1
Response 15 17.523809524
Dispersion and Standard Deviation
Dispersion StdDev
VAR1 5.930408874 9.1682682584
VAR2 2.965204437 3.160771455
VAR3 4.4478066555 5.3585712381
Intercep 0 0
Response 5.930408874 10.171622524
The following are the results of LS regression:
Unweighted Least-Squares Estimation
LS Parameter Estimates
Approx Pr >
Variable Estimate Std Err t Value |t|
VAR1 0.715640 0.134858 5.31 <.0001
VAR2 1.295286 0.368024 3.52 0.0026
VAR3 -0.152123 0.156294 -0.97 0.3440
Intercep -39.919674 11.895997 -3.36 0.0038
Variable Lower WCI Upper WCI
VAR1 0.451323 0.979957
VAR2 0.573972 2.016600
VAR3 -0.458453 0.154208
Intercep -63.2354 -16.603949
Sum of Squares = 178.8299616
Degrees of Freedom = 17
LS Scale Estimate = 3.2433639182
Cov Matrix of Parameter Estimates
VAR1 VAR2 VAR3 Intercep
VAR1 0.018187 -0.036511 0.007144 0.287587
VAR2 -0.036511 0.135442 0.000010 -0.651794
VAR3 -0.007144 0.000011 0.024428 -1.676321
Intercep 0.287587 -0.651794 1.676321 141.514741
R-squared = 0.9135769045
F(3,17) Statistic = 59.9022259
Probability = 3.0163272E-9
These are the LMS results for the 2000 random subsets:
Random Subsampling for LMS
Best
Subset Singular Criterion Percent
500 23 0.163262 25
1000 55 0.140519 50
1500 79 0.140519 75
2000 103 0.126467 100
Minimum Criterion= 0.1264668282
Least Median of Squares (LMS) Method
Minimizing 13th Ordered Squared Residual.
Highest Possible Breakdown Value = 42.86 %
Random Selection of 2103 Subsets
Among 2103 subsets 103 are singular.
Observations of Best Subset
15 11 19 10
Estimated Coefficients
VAR1 VAR2 VAR3 Intercep
0.75 0.5 0 -39.25
LMS Objective Function = 0.75
Preliminary LMS Scale = 1.0478510755
Robust R Squared = 0.96484375
Final LMS Scale = 1.2076147288
For LMS observations, 1, 3, 4, and 21 have scaled residuals larger than 2.5 (table not shown) and are considered outliers. These are the corresponding WLS results:
Weighted Least-Squares Estimation
RLS Parameter Estimates Based on LMS
Approx Pr >
Variable Estimate Std Err t Value |t|
VAR1 0.797686 0.067439 11.83 <.0001
VAR2 0.577340 0.165969 3.48 0.0041
VAR3 -0.067060 0.061603 -1.09 0.2961
Intercep -37.652459 4.732051 -7.96 <.0001
Lower WCI Upper WCI
0.665507 0.929864
0.252047 0.902634
-0.187800 0.053680
-46.927108 -28.37781
Weighted Sum of Squares = 20.400800254
Degrees of Freedom = 13
RLS Scale Estimate = 1.2527139846
Cov Matrix of Parameter Estimates
VAR1 VAR2 VAR3 Intercep
VAR1 0.004548 -0.007921 -0.001199 0.001568
VAR2 -0.007921 0.027546 -0.000463 -0.065018
VAR3 -0.001199 -0.000463 0.003795 -0.246102
Intercep 0.001568 -0.065018 -0.246102 22.392305
Weighted R-squared = 0.9750062263
F(3,13) Statistic = 169.04317954
Probability = 1.158521E-10
There are 17 points with nonzero weight.
Average Weight = 0.8095238095
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.