STAT 350: Lecture 33
Theory of Generalized Linear Models
If Y has a Poisson distribution with parameter ![]() then
then
![]()
for k a non-negative integer. We can use the method of
maximum likelihood to estimate k if we have a sample
![]() of independent Poisson random variables all
with mean
of independent Poisson random variables all
with mean ![]() . If we observe
. If we observe ![]() ,
, ![]() and so
on then the likelihood function is
and so
on then the likelihood function is
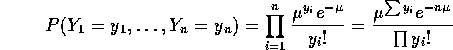
This function of ![]() can be maximized by maximizing its
logarithm, the log likelihood function. We set the derivative of the
log likelihood with respect to
can be maximized by maximizing its
logarithm, the log likelihood function. We set the derivative of the
log likelihood with respect to ![]() equal to 0, getting
equal to 0, getting
![]()
This is the likelihood equation and its solution ![]() is the maximum likelihood estimate of
is the maximum likelihood estimate of ![]() .
.
In a regression problem all the ![]() will have different means
will have different means
![]() . Our log-likelihood is now
. Our log-likelihood is now
![]()
If we treat all n of the ![]() we can maximize the log
likelihood by setting each of the n partial derivatives with
respect to
we can maximize the log
likelihood by setting each of the n partial derivatives with
respect to ![]() for k from 1 to n equal to 0.
The kth of these n equations is just
for k from 1 to n equal to 0.
The kth of these n equations is just
![]()
This leads to ![]() . In glm jargon this model is the
saturated model.
. In glm jargon this model is the
saturated model.
A more useful model is one in which there are fewer parameters but more than 1. A typical glm model is
![]()
where the ![]() are covariate values for the ith observation
(often including an intercept term just as in standard linear
regression).
are covariate values for the ith observation
(often including an intercept term just as in standard linear
regression).
In this case the log-likelihood is
![]()
which should be treated as a function of ![]() and maximized.
and maximized.
The derivative of this log-likelihood with respect to ![]() is
is
![]()
If ![]() has p components then setting these p derivatives
equal to 0 gives the likelihood equations.
has p components then setting these p derivatives
equal to 0 gives the likelihood equations.
It is no longer possible to solve the likelihood equations
analytically. We have, instead, to settle for numerical techniques.
One common technique is called iteratively re-weighted least
squares. For a Poisson variable with mean ![]() the variance
is
the variance
is ![]() . Ignore for a moment the fact that if we
knew
. Ignore for a moment the fact that if we
knew ![]() we would know
we would know ![]() and consider fitting our
model by least squares with the
and consider fitting our
model by least squares with the ![]() known. We would
minimize (see our discussion of weighted least squares)
known. We would
minimize (see our discussion of weighted least squares)
![]()
by taking the derivative with respect to ![]() and (again
ignoring the fact that
and (again
ignoring the fact that ![]() depends on
depends on ![]() we
would get
we
would get
![]()
But the derivative of ![]() with respect to
with respect to ![]() is
is
![]() and replacing
and replacing ![]() by
by ![]() we get the
equation
we get the
equation
![]()
exactly as before. This motivates the following estimation scheme.
Non-linear least squares
In a regression model of the form
![]()
we call the model linear if ![]() for some covariates
for some covariates
![]() and a parameter
and a parameter ![]() . Often, however, we have non-linear
models such as
. Often, however, we have non-linear
models such as ![]() or in general
or in general ![]() for some function f which need not
be linear in
for some function f which need not
be linear in ![]() . If the errors are
homo-scedastic normal errors then the maximum likelihood estimates of
the
. If the errors are
homo-scedastic normal errors then the maximum likelihood estimates of
the ![]() are least squares estimates, minimizing
are least squares estimates, minimizing
![]() . The value
. The value ![]() then solves
then solves
![]()
This equation can usually not be solved analytically. In general the process of solving it numerically is iterative. One approach is:
![]()
where ![]() is the vector of partial derivatives of
is the vector of partial derivatives of ![]() with respect to
the entries in
with respect to
the entries in ![]() .
.
![]()
with respect to ![]() .
.
![]()
where ![]() . The solution is
. The solution is
![]() . We compute this
. We compute this ![]() .
.
Example
In thermoluminescence dating ( see Lecture 1) a common model is
![]()
Thus in this case
![]()
The derivatives of ![]() with respect to the entries of
with respect to the entries of ![]() are
are
![]()
![]()
and
![]()
Software and computing details
In SAS the procedure proc nlin will do non-linear least squares.
You need to specify quite a few ingredients. The model statement must
specify the exact functional form of the function ![]() . You have a
statement parms which is needed to specify the initial guess for
. You have a
statement parms which is needed to specify the initial guess for ![]() .
You usually will have a bunch of der statements to specify derivatives of
the predicted values with respect to each parameter and, if you use some algorithms,
you will even specify some second derivatives. (You get a choice of 5 different
iterative algorithms. The one described above is called Gauss-Newton.)
.
You usually will have a bunch of der statements to specify derivatives of
the predicted values with respect to each parameter and, if you use some algorithms,
you will even specify some second derivatives. (You get a choice of 5 different
iterative algorithms. The one described above is called Gauss-Newton.)
In Splus the function nls can be used to to the same thing.