
I am a PhD student working with Dr. Ping Tan in Gruvi Lab, Simon Fraser University starting from September 2014, I got my Bachelor's degree in Computer Science in 2013 from National University of Defense Technology, P.R. China. I am interested in image and video processing, deep learning, Augmented Reality applications.
Here is my CV.
Recent Publications
Renjiao Yi, Chenyang Zhu,
Ping Tan and Stephen Lin, "Faces as Lighting Probes via Unsupervised Deep Highlight Extraction", ECCV 2018.
We present a method for estimating detailed scene illumination using human faces in a single image. In contrast to previous works that estimate lighting in terms of low-order basis functions or distant point lights, our technique estimates illumination at a higher precision in the form of a non-parametric environment map...
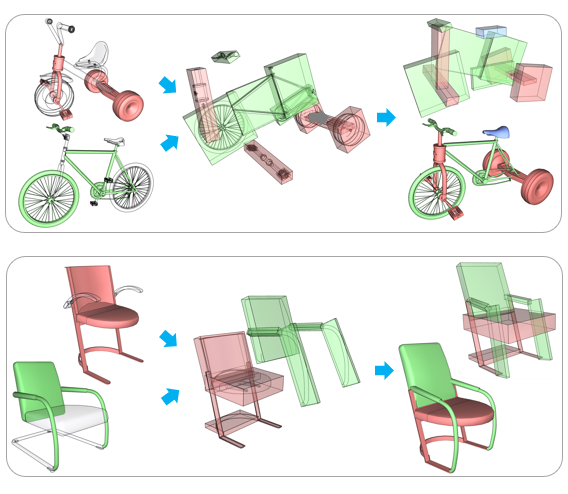
Chenyang Zhu, Kai Xu, Siddhartha Chaudhuri, Renjiao Yi and Hao Zhang,
SCORES: Shape Composition with Recursive Substructure Priors", ACM Transactions on Graphics (SIGGRAPH Asia 2018).
We introduce SCORES, a recursive neural network for shape composition. Our network takes as input sets of parts from two or more source 3D shapes and a rough initial placement of the parts. It outputs an optimized part structure for the composed shape, leading to high-quality geometry construction. A unique feature of our composition network is that it is not merely learning how to connect parts. Our goal is to produce a coherent and plausible 3D shape...

Chenyang Zhu, Renjiao Yi,
Wallace Lira, Ibraheem Alhashim, Kai Xu and Hao Zhang, "Deformation-Driven Shape Correspondence via Shape Recognition", ACM Transactions on Graphics (SIGGRAPH 2017), 36(4): 51, 2017.
Many approaches to shape comparison and recognition start by establishing a shape correspondence. We "turn the table" and show that quality shape correspondences can be obtained by performing many shape recognition tasks. What is more, the method we develop computes a fine-grained, topology-varying part correspondence between two 3D shapes where the core evaluation mechanism only recognizes shapes globally...

Renjiao Yi, Jue Wang, Ping Tan , "Automatic Fence Segmentation in Videos of Dynamic Scenes", IEEE Conference on Computer Vision and Patten Recognition (CVPR), Las Vegas, USA, Jun. 2016.
We present a fully automatic approach to detect and segment fence-like occluders from a video clip. Unlike previous approaches that usually assume either static scenes or cameras, our method is capable of handling both dynamic scenes and moving cameras...
Get In Touch

