Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| The MIXED Procedure |
![\sigma^2{\rm diag}[{\rm exp}({U \delta})]](images/mixeq75.gif)
ods output SolutionF=sf;
proc mixed;
class a;
model y = a x / s;
run;
proc mixed;
class a;
model y = a x;
repeated / local=pom(sf);
run;
ods output SolutionF=sf1;
proc mixed;
class a;
model y = a x / s;
repeated / local=pom(sf);
run;
proc compare brief data=sf compare=sf1;
var estimate;
run;
data sf;
set sf1;
run;
repeated / type=cs subject=person r=1,3,5;
| Structure | Description | Parms | (i,j)th element |
| ANTE(1) | Ante-Dependence | 2t-1 | |
| AR(1) | Autoregressive(1) | 2 | |
| ARH(1) | Heterogeneous AR(1) | t+1 | |
| ARMA(1,1) | ARMA(1,1) | 3 | |
| CS | Compound Symmetry | 2 | |
| CSH | Heterogeneous CS | t+1 | |
| FA(q) | Factor Analytic | [q/2](2t -q + 1) + t | |
| FA0(q) | No Diagonal FA | [q/2](2t -q + 1) | |
| FA1(q) | Equal Diagonal FA | [q/2](2t -q + 1) + 1 | |
| HF | Huynh-Feldt | t+1 | |
| LIN(q) | General Linear | q | |
| TOEP | Toeplitz | t | |
| TOEP(q) | Banded Toeplitz | q | |
| TOEPH | Heterogeneous TOEP | 2t-1 | |
| TOEPH(q) | Banded Hetero TOEP | t+q-1 | |
| UN | Unstructured | t(t+1)/2 | |
| UN(q) | Banded | [q/2](2t-q+1) | |
| UNR | Unstructured Corrs | t(t+1)/2 | |
| UNR(q) | Banded Correlations | [q/2](2t-q+1) | |
| UN@AR(1) | Direct Product AR(1) | t1(t1+1)/2 + 1 | |
| UN@CS | Direct Product CS | t1(t1+1)/2 + 1 | |
| UN@UN | Direct Product UN | t1(t1+1)/2 + | |
| t2(t2+1)/2 - 1 | |||
| VC | Variance Components | q |
| Structure | Description | Parms | (i,j)th element |
| SP(EXP)(c-list) | Exponential | 2 | |
| SP(EXPA)(c-list) | Anisotropic Exponential | 2c + 1 | |
| SP(GAU)(c-list) | Gaussian | 2 | |
| SP(LIN)(c-list) | Linear | 2 | |
| SP(LINL)(c-list) | Linear log | 2 | |
| SP(POW)(c-list) | Power | 2 | |
| SP(POWA)(c-list) | Anisotropic Power | c+1 | |
| SP(SPH)(c-list) | Spherical | 2 | ![\sigma^2[1 - (\frac{3d_{ij}}{2\rho}) +
(\frac{d^3_{ij}}{2\rho^3})]1(d_{ij} \leq \rho)](images/mixeq110.gif) |
| Description | Structure | Example |
| Variance Components | VC (default) | ![[ \sigma_{B}^2 & 0 & 0 & 0 \ 0 & \sigma_{B}^2 & 0 & 0 \ 0 & 0 & \sigma_{AB}^2 & 0 \ 0 & 0 & 0 & \sigma_{AB}^2]](images/mixeq111.gif) |
| Compound Symmetry | CS | ![[ \sigma^2 + \sigma_1 & \sigma_1 & \sigma_1
& \sigma_1 \ \sigma_1 & \sigma^2 + ...
...2 + \sigma_1
& \sigma_1 \ \sigma_1 & \sigma_1 & \sigma_1
& \sigma^2 + \sigma_1]](images/mixeq112.gif) |
| Unstructured | UN | ![[ \sigma^2_{1} & \sigma_{21} & \sigma_{31} & \sigma_{41} \ \sigma_{21} & \sigma...
...a^2_{3} & \sigma_{43} \ \sigma_{41} & \sigma_{42} & \sigma_{43} & \sigma^2_{4}]](images/mixeq113.gif) |
| Banded Main Diagonal | UN(1) | ![[ \sigma^2_1 & 0 & 0 & 0 \ 0 & \sigma^2_2 & 0 & 0 \ 0 & 0 & \sigma^2_3 & 0 \ 0 & 0 & 0 & \sigma^2_4]](images/mixeq114.gif) |
| First-Order Autoregressive | AR(1) | ![\sigma^2[ 1 & \rho & \rho^2 & \rho^3 \ \rho & 1 & \rho & \rho^2 \ \rho^2 & \rho & 1 & \rho \ \rho^3 & \rho^2 & \rho & 1]](images/mixeq115.gif) |
| Toeplitz | TOEP | ![[ \sigma^2 & \sigma_1 & \sigma_2 & \sigma_3 \ \sigma_1 & \sigma^2 & \sigma_1 & ...
...2 & \sigma_1 & \sigma^2 & \sigma_1 \ \sigma_3 & \sigma_2 & \sigma_1 & \sigma^2]](images/mixeq116.gif) |
| Toeplitz with Two Bands | TOEP(2) | ![[ \sigma^2 & \sigma_1 & 0 & 0 \ \sigma_1 & \sigma^2 & \sigma_1 & 0 \ 0 & \sigma_1 & \sigma^2 & \sigma_1 \ 0 & 0 & \sigma_1 & \sigma^2]](images/mixeq117.gif) |
| Spatial Power | SP(POW)(c) | ![\sigma^2[ 1 & \rho^{d_{12}} & \rho^{d_{13}} & \rho^{d_{14}} \ \rho^{d_{21}} & 1...
..._{32}} & 1 & \rho^{d_{34}} \ \rho^{d_{41}} & \rho^{d_{42}} & \rho^{d_{43}} & 1]](images/mixeq118.gif) |
| Heterogeneous AR(1) | ARH(1) | ![[ \sigma_{1}^2 & \sigma_{1}\sigma_{2}\rho &
\sigma_{1}\sigma_{3}\rho^2 & \sigm...
...1}\rho^3 & \sigma_{4}\sigma_{2}\rho &
\sigma_{4}\sigma_{3}\rho & \sigma_{4}^2]](images/mixeq119.gif) |
| First-Order Autoregressive Moving-Average | ARMA(1,1) | ![\sigma^2[ 1 & \gamma & \gamma\rho & \gamma\rho^2 \ \gamma & 1 & \gamma & \gamma\rho \ \gamma\rho & \gamma & 1 & \gamma \ \gamma\rho^2 & \gamma\rho & \gamma & 1]](images/mixeq120.gif) |
| Heterogeneous CS | CSH | ![[ \sigma_{1}^2 & \sigma_{1}\sigma_{2}\rho & \sigma_{1}\sigma_{3}\rho
& \sigma_{...
...a_{1}\rho & \sigma_{4}\sigma_{2}\rho & \sigma_{4}\sigma_{3}\rho
& \sigma_{4}^2]](images/mixeq121.gif) |
| First-Order Factor Analytic | FA(1) | ![[ \lambda_{1}^2 + d_{1} & \lambda_{1}\lambda_{2} & \lambda_{1}\lambda_{3}
& \la...
..._{1} & \lambda_{4}\lambda_{2} & \lambda_{4}\lambda_{3}
& \lambda_{4}^2 + d_{4}]](images/mixeq122.gif) |
| Huynh-Feldt | HF | ![[ \sigma_{1}^2 & \frac{\sigma_{1}^2+\sigma_{2}^2}2-\lambda
& \frac{\sigma_{1}^...
...ma_{1}^2}2-\lambda
& \frac{\sigma_{3}^2+\sigma_{2}^2}2-\lambda & \sigma_{3}^2]](images/mixeq123.gif) |
| First-Order Ante-dependence | ANTE(1) | ![[ \sigma^2_1 &
\sigma_1 \sigma_2 \rho_1 &
\sigma_1 \sigma_3 \rho_1 \rho_2 \ \...
... \ \sigma_3 \sigma_1 \rho_2 \rho_1 &
\sigma_3 \sigma_2 \rho_2 &
\sigma^2_3 \]](images/mixeq124.gif) |
| Heterogeneous Toeplitz | TOEPH | ![[ \sigma^2_1 &
\sigma_1 \sigma_2 \rho_1 &
\sigma_1 \sigma_3 \rho_2 &
\sigma_...
...\rho_3 &
\sigma_4 \sigma_2 \rho_2 &
\sigma_4 \sigma_3 \rho_1 &
\sigma^2_4 \]](images/mixeq125.gif) |
| Unstructured Correlations | UNR | ![[ \sigma^2_1 &
\sigma_1 \sigma_2 \rho_{21} &
\sigma_1 \sigma_3 \rho_{31} &
\...
... &
\sigma_4 \sigma_2 \rho_{42} &
\sigma_4 \sigma_3 \rho_{43} &
\sigma^2_4 \]](images/mixeq126.gif) |
| Direct Product AR(1) | UN@AR(1) | ![[ \sigma^2_{1} & \sigma_{21} \ \sigma_{21} & \sigma^2_{2}
]
\otimes
[ 1 & \rho & \rho^2 \ \rho & 1 & \rho \ \rho^2 & \rho & 1
] =](images/mixeq127.gif) |
![[ \sigma^2_{1} & \sigma^2_{1}\rho & \sigma^2_{1} \rho^2 &
\sigma_{21} & \sigma...
...rho & \sigma_{21} &
\sigma^2_{2} \rho^2 & \sigma^2_{2} \rho & \sigma^2_{2} \ ]](images/mixeq128.gif) |
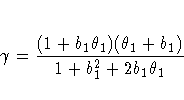
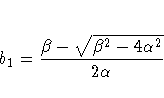
![\sigma^2 \prod_{k=1}^c \exp [-\theta_k d(i,j,k)^{p_k}]](images/mixeq143.gif)
repeated / type=sp(expa)(c1 c2 c3)
subject=intercept;
parms (3) (4) (5) (2) (2) (2) (1) /
hold=4,5,6;
proc mixed;
class Var Year Child;
model Y = Var Year Var*Year;
repeated Var Year / type=un@ar(1)
subject=Child;
run;
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.