Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| The PHREG Procedure |
The analysis of survival data requires special techniques because the data are almost always incomplete, and familiar parametric assumptions may be unjustifiable. Investigators follow subjects until they reach a prespecified endpoint (for example, death). However, subjects sometimes withdraw from a study, or the study is completed before the endpoint is reached. In these cases, the survival times (also known as failure times) are censored; subjects survived to a certain time beyond which their status is unknown. The noncensored survival times are referred to as event times. Methods for survival analysis must account for both censored and noncensored data.
There are many types of models that have been used for survival data. Two of the more popular types of models are the accelerated failure time model (Kalbfleisch and Prentice 1980) and the Cox proportional hazards model (Cox 1972). Each has its own assumptions on the underlying distribution of the survival times. Two closely related functions often used to describe the distribution of survival times are the survivor function and the hazard function (see the section "Failure Time Distribution" for definitions).
The accelerated failure time model assumes a parametric form for the effects of the explanatory variables and usually assumes a parametric form for the underlying survivor function. Cox's proportional hazards model also assumes a parametric form for the effects of the explanatory variables, but it allows an unspecified form for the underlying survivor function.
The PHREG procedure performs regression analysis of survival data based on the Cox proportional hazards model. Cox's semiparametric model is widely used in the analysis of survival data to explain the effect of explanatory variables on survival times.
The survival time of each member of a population is assumed to follow its own hazard function, hi(t), expressed as
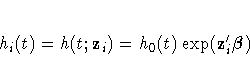
The survivor function can be expressed as
![S(t;z_{i}) = [S_{0}(t)]^{ {\rm exp}(z'_{i}{\beta})}](images/phreq3.gif)
To estimate ![]() , Cox (1972, 1975) introduced the partial
likelihood function, which
eliminates the unknown baseline hazard h0(t) and
accounts for censored survival times.
The partial likelihood of Cox also allows time-dependent
explanatory variables.
An explanatory variable is time-dependent if
its value for any given individual can change over time.
Time-dependent variables have many useful applications in
survival analysis. You can use a time-dependent variable to
model the effect of subjects changing treatment groups. Or
you can include time-dependent variables such as blood
pressure or blood chemistry measures that vary with time
during the course of a study. You can also use
time-dependent variables to test the validity of the
proportional hazards model.
, Cox (1972, 1975) introduced the partial
likelihood function, which
eliminates the unknown baseline hazard h0(t) and
accounts for censored survival times.
The partial likelihood of Cox also allows time-dependent
explanatory variables.
An explanatory variable is time-dependent if
its value for any given individual can change over time.
Time-dependent variables have many useful applications in
survival analysis. You can use a time-dependent variable to
model the effect of subjects changing treatment groups. Or
you can include time-dependent variables such as blood
pressure or blood chemistry measures that vary with time
during the course of a study. You can also use
time-dependent variables to test the validity of the
proportional hazards model.
An alternative way to fit models with time-dependent explanatory variables is to use the counting process style of input. The counting process formulation allows PROC PHREG to fit a superset of the Cox model, known as the multiplicative hazards model. This extension also includes multiple events per subject, time-dependent strata, and left truncation of failure times. The theory of these models is based on the counting process pioneered by Andersen and Gill (1982), and the model is often referred to as the Andersen-Gill Model.
The population under study may consist of a number of subpopulations, each of which has its own baseline hazard function. PROC PHREG performs a stratified analysis to adjust for such subpopulation differences. Under the stratified model, the hazard function for the jth individual in the ith stratum is expressed as
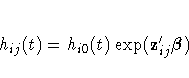
Variable selection is a typical exploratory exercise in multiple regression when the investigator is interested in identifying important prognostic factors from a large number of candidate variables. The PHREG procedure provides four model selection methods: forward selection, backward elimination, stepwise selection, and best subset selection. The best subset selection method is based on the likelihood score statistic. This method identifies a specified number of best models containing one, two, three variables and so on, up to the single model containing all of the explanatory variables.
The PHREG procedure also enables you to
The remaining sections of this chapter contain information on how to use PROC PHREG, information on the underlying statistical methodology, and some sample applications of the procedure. The "Getting Started" section introduces PROC PHREG with two examples. The "Syntax" section describes the syntax of the procedure. The "Details" section summarizes the statistical techniques employed in PROC PHREG. The "Examples" section includes eight additional examples of useful applications. Experienced SAS/STAT software users may decide to proceed to the "Syntax" section, while other users may choose to read both the "Getting Started" and "Examples" sections before proceeding to "Syntax" and "Details."
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.