Computational Method
For a stratified clustered sample design, observations
are represented by an n ×(p+2) matrix
-
(w, y, X) = (whij, yhij, xhij)
where
- w denotes the sampling weight vector
- y denotes the dependent variable
- X denotes the design matrix. (When an
effect contains only classification variables,
the columns of X corresponding to
this effect contain only 0s and 1s; no
reparameterization is made.)
- h = 1, 2, ... , H is the stratum number
with a total of H strata
- i = 1, 2, ... , nh is the cluster number within
stratum h, with a total of nh clusters
- j = 1, 2, ... , mhi is the unit number
within cluster i of stratum h, with a total
of mhi units
- p is the total number of parameters (including
an intercept if the INTERCEPT effect is included
in the MODEL statement)
-
 is the
total number of observations in the sample
is the
total number of observations in the sample
Also, fh denotes the sampling rate for stratum h.
You can use the TOTAL= option or the RATE= option to
input population totals or sampling rates. See
the section "Specification of Population Totals and Sampling Rates" for details. If you input stratum
totals, PROC SURVEYREG computes fh as the ratio of
the stratum sample size to the stratum total. If you
input stratum sampling rates, PROC SURVEYREG uses
these values directly for fh. If you do not
specify the TOTAL= option or the RATE= option, then
the procedure assumes that the stratum sampling rates
fh are negligible, and a finite population
correction is not used when computing variances.
Regression Coefficients
PROC SURVEYREG solves the normal equations  using a modified sweep
routine that produces a generalized (g2) inverse
(X'WX)- and a solution (Pringle and Raynor
1971)
using a modified sweep
routine that produces a generalized (g2) inverse
(X'WX)- and a solution (Pringle and Raynor
1971)
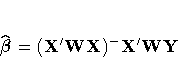
where
W is the diagonal matrix constructed from
WEIGHT variable values.
For models with class variables, there are more design
matrix columns than there are degrees of freedom (DF)
for the effect. Thus, there are linear dependencies
among the columns. In this case, the parameters are not
estimable; there is an infinite number of least-squares
solutions. PROC SURVEYREG uses a generalized (g2)
inverse to obtain values for the estimates. The
solution values are not displayed unless you specify the
SOLUTION option in the MODEL statement. The solution has
the characteristic that estimates are 0 whenever the
design column for that parameter is a linear combination
of previous columns. (Strictly termed, the solution
values should not be called estimates.) With this full
parameterization, hypothesis tests are constructed to
test linear functions of the parameters that are
estimable.
PROC SURVEYREG uses the Taylor series expansion
theory to estimate the covariance-variance matrix of
the estimated regression coefficients (Fuller
1975). Let
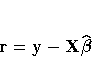
where the (h,i,j)th element is rhij. Compute
1×p row vectors

and calculate the p×p matrix
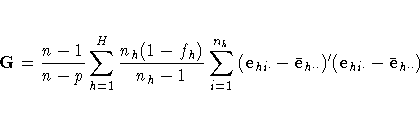
PROC SURVEYREG computes the covariance matrix of  as
as
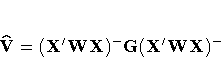
For each effect in the model, PROC SURVEYREG computes
an L matrix such that every element of  is estimable; the L matrix has the
maximum possible rank associated with the effect. To
test the effect, the procedure uses the Wald F
statistic for the hypothesis
is estimable; the L matrix has the
maximum possible rank associated with the effect. To
test the effect, the procedure uses the Wald F
statistic for the hypothesis  . The Wald F statistic equals
. The Wald F statistic equals
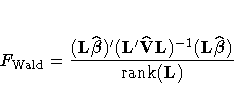
with numerator degrees of freedom equal to rank(L) and denominator degrees of freedom
equal to the number of clusters minus the number of
strata (unless you have specified the denominator
degrees of freedom with the DF= option in the MODEL
statement; see the section "Denominator Degrees of Freedom"). It is possible that
the L matrix cannot be constructed for an
effect, in which case that effect is not testable. For
more information on how the matrix L is
constructed, see the discussion in Chapter 12, "The Four Types of Estimable Functions."
Multiple R-squared
PROC SURVEYREG computes a multiple R-squared for
the weighted regression as
-
R2 = 1-[(SSerror)/(SStotal)]
where SSerror is the error sum of squares
in the ANOVA table
-
SSerror = r'Wr
and SStotal is the total sum of squares
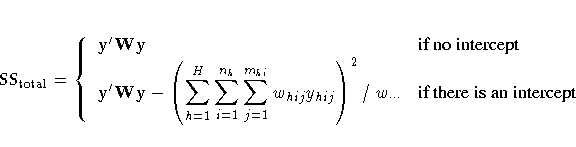
where w··· is the sum of the
sampling weights over all observations.
Root Mean Square Errors
PROC SURVEYREG computes the square root of mean
square errors as

where w··· is the sum of the sampling
weights over all observations.
Design Effect
If you specify the DEFF option in the MODEL statement,
PROC SURVEYREG calculates the design effects for the
regression coefficients.
The design effect of an estimate is the ratio of the
actual variance to the variance computed under the
assumption of simple random sampling.
-
DEFF = [ Variance under the Sample Design/ Variance under Simple Random Sampling]
Refer to Kish (1965, p.258).
PROC SURVEYREG computes the numerator as described in
the section "Variance Estimation". And the denominator is computed
under the assumption that the sample design is simple
random sampling, with no stratification and no
clustering.
To compute the variance under the assumption of simple
random sampling, PROC SURVEYREG calculates the
sampling rate as follows. If you specify both
sampling weights and sampling rates (or population
totals) for the analysis, then the sampling rate under
simple random sampling is calculated as
-
fSRS = n / w···
where n is the sample size and w··· (the sum of the weights over all observations)
estimates the population size. If the sum of the
weights is less than the sample size, fSRS is
set to zero. If you specify sampling rates for the
analysis but not sampling weights, then PROC SURVEYREG
computes the sampling rate under simple random
sampling as the average of the stratum sampling rates.
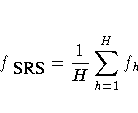
If you do not specify sampling rates (or population
totals) for the analysis, then the sampling rate under
simple random sampling is assumed to be zero.
-
fSRS = 0
Assuming that PROC SURVEYREG collapses single-unit strata
h1, h2, ... , hc
into the pooled stratum, the procedure calculates
the sampling rate for the pooled stratum as
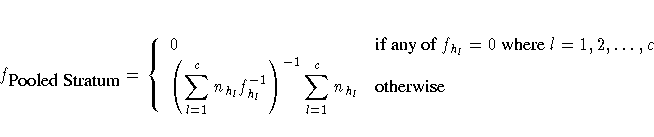
Contrasts
You can use the CONTRAST statement to perform custom
hypothesis tests. If the hypothesis is testable in the
univariate case, the Wald F statistic for  is computed as
is computed as
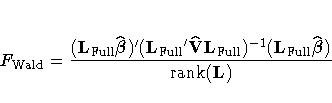
where L is the contrast vector or matrix you specify,
is the vector of regression parameters,
 ,
,  is the estimated covariance matrix of
is the estimated covariance matrix of
 , rank(L) is the rank of
L, and LFull is a matrix such that
, rank(L) is the rank of
L, and LFull is a matrix such that
- -
- LFull has the same
number of columns as L
- -
- LFull has full row rank
- -
- the rank of LFull equals
the rank of the L matrix
- -
- all rows of LFull are
estimable functions
- -
- the Wald F statistic computed using
the LFull matrix is equivalent to
the Wald F statistic computed using the L
matrix with any row deleted that is a linear
combination of previous rows
If L is a full-rank matrix, and all rows of L are estimable functions, then LFull
is the same as L. It is possible that LFull matrix cannot be constructed for contrasts in a
CONTRAST statement, in which case the contrasts are not
testable.
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.