In this raw state, the logfile data provides only a rough sense of the volume of traffic passing through a given server. Simple scripts that perform basic logfile analysis are readily available from various sources on the Internet. (18) However all of the existing scripts I have examined simply treat the logfile transactions as a collection of discrete page requests. They make no attempt to connect these discrete page requests into a "session," to produce a chronological record of each individual reader's interaction with the entirety of the server's published material.
Typically these existing scripts will summarize logfile transactions by grouping them:
providing totals and percentage breakdowns for each category. While such analyses are of interest to a Web server administrator, they do not address the issues most of interest to publishing researchers, particularly those interested in the processes at work when readers interact with hypertext material. Investigating such issues would involve asking questions like the following: (19)
One of my goals with this internship was to begin to explore these kinds of issues, using the Hip Webzine as a "real world" example of an Internet publication. At Hip I was fortunate to have access to archives of logfile data covering most of the time period in which the Hip Webzine was published. As mentioned at the start of Part 2 of this paper, the first issue of the Webzine appeared in September of 1994. As of this writing the most recent issue was Issue 9, which appeared during the third week of August, 1995.
Logfile records at either end of this period were not available for examination: records older than November of 1994 had not been retained, and a new version of the Web server software, installed at Hip in early June of 1995, resulted in invalid logfile data from that date. Apart from these two undocumented periods, there were only minor episodes of data loss, the result of Web server failures of one sort or another. As a result the data on-hand represented a unique record of a webzine's history, showing both its growth and its decline.
Since Hip's Web server serviced all of Hip's Web clients, the logfiles would contain data about interactions between two of these site's pages, as well as activity within any single site (e.g. the Webzine) itself.
It is important to realize that, despite the richness of the data record, it is
far from being a complete picture of reader (or publisher) activity. The various
limitations inherent to the data, as well as some unavoidable assumptions that
were made, are discussed at greater length below.
The volume of data generated by the Web server was enormous. During the month of
May, 1995, for example, approximately 4 megabytes of logfile data were being
generated daily.
2.4.1 - Extraction of relevant data
Because of this, and in an attempt to simplify the subsequent analysis, I decided
to break down the data extraction process into discrete stages, writing a
sequence of three Perl scripts to examine the logfile data, rather than a single,
more complex script. The full text of the three scripts is included as Appendix
B.
The first script in the sequence (referred to as the "sessions.pl" script), goes
through a sequence of logfiles, filtering out records which were of no interest,
and reducing the information into a compact form that was session (or
page-sequence) based, rather than "hit" (or page-reference) based. This reduced
information was stored in an intermediate file referred to as the ".ssn" - for
"session" - file.
2.4.1.1 - The "sessions.pl" script
Each record in the ".ssn" file records a single session: one reader's interaction with the Web server's pages of linked material. Each ".ssn" record includes:
An extract from a typical ".ssn" file is provided in Appendix D of this paper.
The "sessions.pl" script also produced a second intermediate file, referred to as the ".pgs" - for "pages" - file. Each record in the ".pgs" file contains information related to the usage of a specific page amongst all those made available on the Web server. Each ".pgs" record includes:
As output from this script, two more intermediate files are produced: the ".trn" - for "transitions" - file, and the ".trs" - for "transitions sorted" - file. Both files contain exactly the same data, sorted in two different ways. In the ".trn" file the inter-page transitions are sorted by the "from page," or originating page, of a transition. In the ".trs" file the inter-page transitions are sorted by frequency of transition, from the most frequently used transition to the least frequently used.
Each record in the ".trn" file or the ".trs" file contains information on a specific inter-page transition:
An extract from a typical ".trs" file is provided in Appendix D of this paper.
The third script in the sequence goes through all of the intermediate files to
extract and report on data which is specific to sessions involving pages of the
Hip Webzine. Note again that the Hip Web server maintains pages for a variety of
Hip's clients, in addition to the Webzine's pages. Since the Webzine's pages
represent only a small portion of the server's total, only a subset of the
logfile data pertained directly to the Webzine.
2.4.1.3 - The "hipstats.pl" script
Since the two earlier scripts in the sequence make no assumptions about which pages are of interest, the intermediate files will contain a complete record of all Web server activity. The purpose of the third script is to take a closer look at a specific segment of that data. This structure was intended to make it easy for Hip to "plug in" an alternate script as the third stage, to take a closer look at other segments of the server's data: on behalf of a paying client for example.
The nine reports produced by the "hipstats.pl" script are divided into three categories:
Page-based reports: these four reports provide detailed information on specific pages of the Hip Webzine, including the "hit" rate for each page of each Webzine column, the completion ratio for two-page articles, and simple bar charts showing the relative popularity of each page.Session-based reports: these two reports provide bar charts showing the distribution of session time amongst all visits to the Webzine.
Transition-based reports: these three reports provide a list of the "top ten" inter-page transitions. They focus on ways in which Webzine readers enter and leave the Webzine (as far as can be determined), and point out the most popular paths within the Webzine itself.
While many networking environments provide each workstation with its own network address, for security reasons some other environments hide all of their machines behind a single "firewall" machine. This firewall acts as a gateway for all network traffic into and out of that environment, with the side effect that network traffic originating from any of the machines behind the firewall appear to be coming from the same network address. The Web server has no way of distinguishing between individual machines behind the same firewall, with the result that simultaneous visits to the Webzine from two separate machines behind the same firewall will be intermingled, and treated by the "sessions.pl" script as one session. It is my (unsupported) feeling, though, that such intermingling of sessions would be rare, although it is clearly an issue which should be examined more closely.
As noted earlier in this paper, "page caching" can result in gaps in the Web server's logfile. Page caching can be either local to the reader's browser software; it can also occur remotely, on a proxy Web server. Page caching can cause a reader's request for a specific page to be satisfied from a cache of recently (or frequently) referenced pages. Such page references will satisfy the reader's request (displaying the requested page) without the server's intervention, resulting in a gap in the session record.
Again, however, it is important to note that the logfile only records the server's activity: extrapolating a reader's actions from this record is risky. On many Web servers there is nothing to prevent readers from "hunting" for pages by requesting specific directories by name. Such activity will be logged, but will not provide any insights into the reading of hypertexts.
However in any longer-term study, it would be important to be able to uniquely identify individual readers, so that their interaction with a given hypertext publication could be studied over an extended period of time.
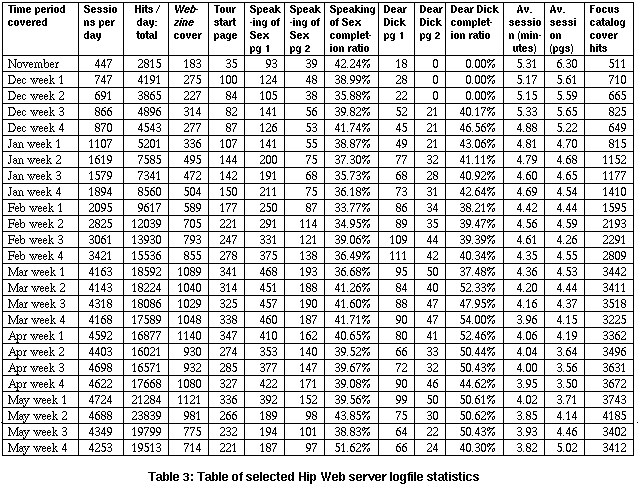
That having been said, the results of the analysis I did undertake, based on the data extracted as described above, are as follows. Table 3 contains a selection of the statistics extracted from archives of the Hip Web server's logfile over the period from November, 1994, to the end of May, 1995. Each column in that table contains the values for a specific measurement, or metric, chosen from the much wider assortment of all metrics gathered by the scripts. In choosing these metrics over others, I was looking for ways to investigate behavior specific to the Hip Webzine (from amongst all server activity). I was also looking for general trends, and patterns of behavior, which might suggest areas for further research.
In most cases the figures represent average daily values for the metric over the stated period. To illustrate with reference to Table 3: during the second week of February, 1995, Hip's Web server recorded an average of 2825 sessions per day. Those sessions averaged 4.56 minutes each, and an average of 4.59 pages were visited in each session. (21) Each day that week an average of 12039 requests were recorded, totaling over all pages on the server. Most of the remaining columns record the average number of daily requests for specific pages: the Webzine cover page (under any of its aliases); the first page of the Hip tour; pages 1 and 2 of two of the Webzine's most popular columns; and for comparison, the Focus catalog cover page. The remaining two columns give the completion ratio for the two Webzine columns.
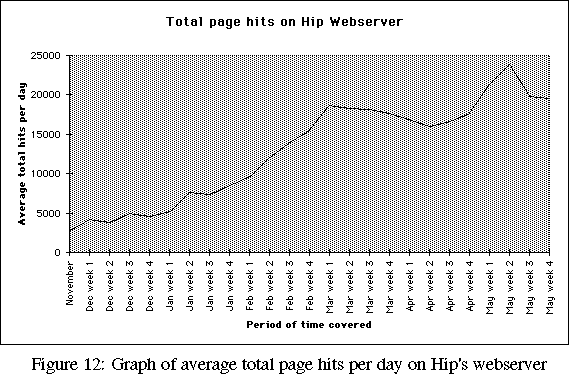
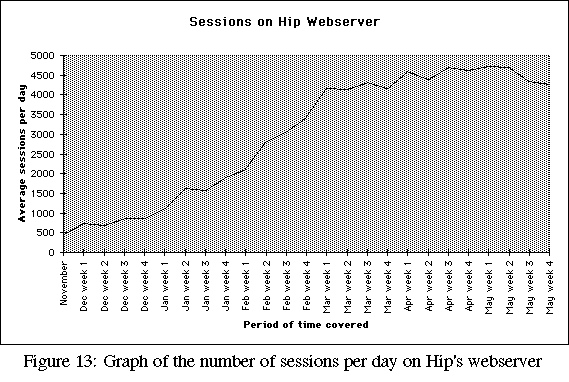
The first two graphs (Figures 12 and 13) show the steady growth of traffic on Hip's Web server. Both the number of page hits, and the number of sessions, show a similar growth pattern over the period. When considered against the background of overall Web traffic growth however, the trends on Hip's server are hardly surprising.
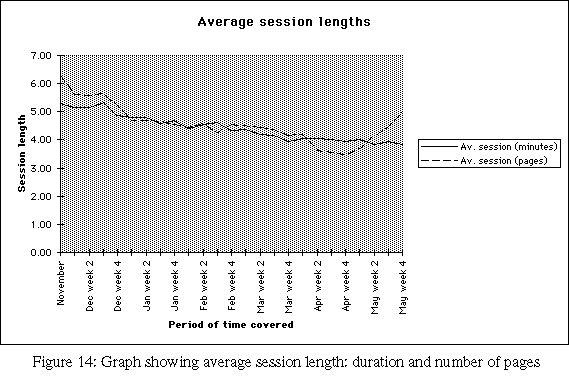
The graph in Figure 14 is more interesting, showing the average length of sessions for readers visiting Hip's server. While there is much anecdotal evidence of Web surfers' brief attention span, this graph provides the first numeric evidence of this behavior that I have seen. Session lengths declined slightly, but remained fairly constant throughout the entire period. One possible reason for the gradual decline in session lengths is the overall growth in traffic on the Hip server: as the demand for pages grows, the server would be less responsive to individual page requests, motivating people to browse elsewhere on the Web. Examining changes in the average intervals between page requests within a session might provide additional data: a less responsive server should result in longer intervals between pages, in addition to the possible effects on total session length.
It would valuable to try varying those parameters in the "sessions.pl" script which define a session. For example the criterion used for deciding when a session ends was "more than five minutes between page requests." If this value were increased to ten minutes or more, with no significant effect on the graph in Figure 14, then we could be more assured of the accuracy of the session length data.
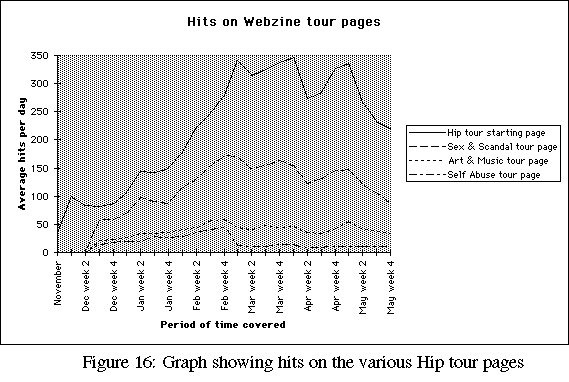
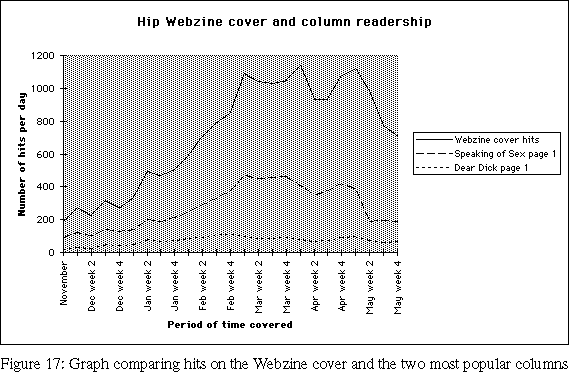
Figures 15, 16, and 17 are intended to show the distribution of activity within the pages of the Hip Webzine. Only most frequently referenced pages are noted: the Webzine cover page (under any of its aliases); the first pages of the "Speaking of Sex" and "Dear Dick" columns; and a selection of the "departmental tour" pages.
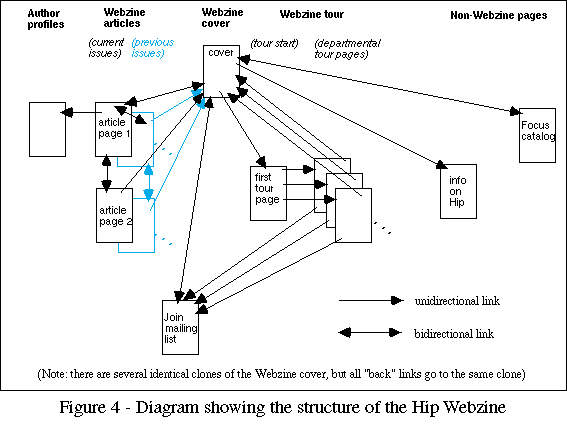
The cover pages were referenced much more frequently than any other Webzine page, for the simple reason that the Webzine's structure directed readers back to the cover from every subsidiary page (Figure 4). This is good Web page design at work: always provide readers with a way "back" to some well-known reference point, to help them get their bearings if they become disoriented.
The other feature worth noting with these graphs is the rise and fall of the Webzine's readership. Unfortunately the period covered by the logfiles ends in May, but this same trend can be seen in Figure 10, showing Webzine mailing list activity continuing to decline through July.
Readers came to the Webzine in one of two ways: either by explicitly typing the Webzine's URL into their browser, or by clicking on an existing link from some other Web site. Readers may have read about the Webzine in another media outlet (and the Webzine did get reviewed on one or two occasions), or in typical Web browsing fashion, they may have clicked on a link to see where it would lead. In either case curiosity was likely the motivating force.
Once at the Webzine's cover, a typical new reader would take the Webzine tour, and get a sense of the publication's style. Those who were interested enough would register their EMail addresses with the Hip mailing list, and then proceed back to the cover page to examine the current issue's table of contents. Not surprisingly, the "Sex & Scandal" section attracted the most interest from readers; such material is usually successful in drawing in the curious. Readers would then examine an article or two - rarely to completion, even though the articles were just two pages long - before "surfing" off to some other Web site. The entire visit would have lasted approximately five minutes, and only four or five pages of the Webzine's total of thirty to forty pages would have been viewed. Based on this behaviour, Webzine visitors could more accurately be termed "browsers" than "readers."
One can assume that return visits to the Webzine were rarely spontaneous, since interested readers were likely to have added their names to the mailing list, and would await a message from Jane announcing the appearance of a new issue. There is some evidence in the logfile that messages from Jane were followed by a slight peak in Webzine visits. Although logfile data does not allow us to distinguish between return visits and first time visits, I would expect to find some differences in readership behaviour between first-time and return visits.
Return visitors would do less "exploring," since they would already have a sense of the Webzine's style and structure. This behaviour would be related to the publication schedule: weekly issues would result in readers who were more familiar with the publication; monthly (or less frequent) issues would result in return visits that more closely resembled first-time ones. Return visits should show fewer visits to the Webzine tour pages, and less visits to columns already found to be of little interest. With a regular publication schedule I would expect to find readers' return visits shorter in terms of the number of pages visited, and more "linear" in the order that those pages were read.
Footnote 19:
Appendix E contains a report written for Dick
Hardt, providing a detailed rationale for the gathering of various metrics by Web
servers. (back)
Footnote 20:
Note, though, that there is a degree of circularity in this reasoning, since the
session length numbers are derived from sessions extracted using the five-minute
cutoff value. (back)
Footnote 21:
Note again that, as defined here, sessions need not consist of Webzine pages
alone. In fact, because of the cross-linking of material on Hip's Web server,
Webzine readers frequently visited other, non-Webzine material on Hip's server,
and vice versa. (back)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}