Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| The MODEL Procedure |
The different solution modes are explained in detail in the following sections.
A static solution refers to a solution obtained by using the actual values when available for the lagged endogenous values. Static mode is used to simulate the behavior of the model without the complication of previous period errors. Dynamic simulation is the default.
If you wish to use static values for lags only for the first n observations, and dynamic values thereafter, specify the START=n option. For example, if you want a dynamic simulation to start after observation twenty-four, specify START=24 on the SOLVE statement. If the model being simulated had a value lagged for four time periods, then this value would start using dynamic values when the simulation reached observation number 28.
To see how well a model predicts n time periods in the future, perform an n-period-ahead forecast on real data and compare the forecast values with the actual values.
n-period-ahead forecasting refers to using dynamic values for the lagged endogenous variables only for lags 1 through n-1. For example, 1-period-ahead forecasting, specified by the NAHEAD=1 option on the SOLVE statement, is the same as if a static solution had been requested. Specifying NAHEAD=2 produces a solution that uses dynamic values for lag one and static, actual, values for longer lags.
The following example is a 2-year-ahead dynamic simulation. The output is shown in Figure 14.59.
data yearly;
input year x1 x2 x3 y1 y2 y3;
datalines;
84 4 9 0 7 4 5
85 5 6 1 1 27 4
86 3 8 2 5 8 2
87 2 10 3 0 10 10
88 4 7 6 20 60 40
89 5 4 8 40 40 40
90 3 2 10 50 60 60
91 2 5 11 40 50 60
;
run;
proc model data=yearly outmodel=foo;
endogenous y1 y2 y3;
exogenous x1 x2 x3;
y1 = 2 + 3*x1 - 2*x2 + 4*x3;
y2 = 4 + lag2( y3 ) + 2*y1 + x1;
y3 = lag3( y1 ) + y2 - x2;
solve y1 y2 y3 / nahead=2 out=c;
run;
proc print data=c;run;
|
|
The proceding 2-year-ahead simulation can be emulated without using the NAHEAD= option by the following PROC MODEL statements:
proc model data=test model=foo;
range year = 87 to 88;
solve y1 y2 y3 / dynamic solveprint;
run;
range year = 88 to 89;
solve y1 y2 y3 / dynamic solveprint;
run;
range year = 89 to 90;
solve y1 y2 y3 / dynamic solveprint;
run;
range year = 90 to 91;
solve y1 y2 y3 / dynamic solveprint;
The totals shown under "Observations Processed" in Figure 14.59
are equal to the sum of the four individual runs.
In forecast mode, PROC MODEL solves only for those endogenous variables that are missing in the data set. The actual value of an endogenous variable is used as the solution value whenever nonmissing data for it are available in the input data set. Forecasting is selected by the FORECAST option on the SOLVE statement. For example, an econometric forecasting model can contain an equation to predict future tax rates, but tax rates are usually set in advance by law. Thus, for the first year or so of the forecast, the predicted tax rate should really be exogenous. Or, you may want to use a prior forecast of a certain variable from a short-run forecasting model to provide the predicted values for the earlier periods of a longer-range forecast of a long-run model. A common situation in forecasting is when historical data needed to fill the initial lags of a dynamic model are available for some of the variables but have not yet been obtained for others. In this case, the forecast must start in the past to supply the missing initial lags. Clearly, you should use the actual data that are available for the lags. In all the preceding cases, the forecast should be produced by running the model in the FORECAST mode; simulating the model over the future periods would not be appropriate.
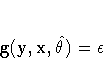
The RANDOM= option is used to request Monte Carlo (or stochastic)
simulations to generate confidence intervals for errors arising
from the first two sources.
The Monte Carlo simulations can be performed with ![]() ,
,
![]() ,
or both vectors represented as random variables.
The SEED= option is used to control the random number generator
for the simulations.
SEED=0 forces the random number generator to use the system clock
as its seed value.
,
or both vectors represented as random variables.
The SEED= option is used to control the random number generator
for the simulations.
SEED=0 forces the random number generator to use the system clock
as its seed value.
In Monte Carlo simulations, repeated simulations are performed on the model
for random perturbations of the parameters and the additive error term.
The random perturbations follow a multivariate normal distribution
with expected value of
0 and covariance described by a covariance matrix of the parameter estimates
in the case of ![]() ,or a covariance matrix of the equation residuals for the case of
,or a covariance matrix of the equation residuals for the case of
![]() . PROC MODEL can generate both covariance matrices or
you can provide them.
. PROC MODEL can generate both covariance matrices or
you can provide them.
The ESTDATA= option specifies a data set containing an estimate of the covariance matrix of the parameter estimates to use for computing perturbations of the parameters. The ESTDATA= data set is usually created by the FIT statement with the OUTEST= and OUTCOV options. When the ESTDATA= option is specified, the matrix read from the ESTDATA= data set is used to compute vectors of random shocks or perturbations for the parameters. These random perturbations are computed at the start of each repetition of the solution and added to the parameter values. The perturbed parameters are fixed throughout the solution range. If the covariance matrix of the parameter estimates is not provided, the parameters are not perturbed.
The SDATA= option specifies a data set containing the covariance matrix of the residuals to use for computing perturbations of the equations. The SDATA= data set is usually created by the FIT statement with the OUTS= option. When SDATA= is specified, the matrix read from the SDATA= data set is used to compute vectors of random shocks or perturbations for the equations. These random perturbations are computed at each observation. The simultaneous solution satisfies the model equations plus the random shocks. That is, the solution is not a perturbation of a simultaneous solution of the structural equations; rather, it is a simultaneous solution of the stochastic equations using the simulated errors. If the SDATA= option is not specified, the random shocks are not used.
The different random solutions are identified by the _REP_ variable in the OUT= data set. An unperturbed solution with _REP_=0 is also computed when the RANDOM= option is used. RANDOM=n produces n+1 solution observations for each input observation in the solution range. If the RANDOM= option is not specified, the SDATA= and ESTDATA= options are ignored, and no Monte Carlo simulation is performed.
PROC MODEL does not have an automatic way of modeling the exogenous variables as random variables for Monte Carlo simulation. If the exogenous variables have been forecast, the error bounds for these variables should be included in the error bounds generated for the endogenous variables. If the models for the exogenous variables are included in PROC MODEL, then the error bounds created from a Monte Carlo simulation will contain the uncertainty due to the exogenous variables.
Alternatively, if the distribution of the exogenous variables is known, the built-in random number generator functions can be used to perturb these variables appropriately for the Monte Carlo simulation. For example, if you knew the forecast of an exogenous variable, X, had a standard error of 5.2 and the error was normally distributed, then the following statements could be used to generate random values for X:
x_new = x + 5.2 * rannor(456);During a Monte Carlo simulation the random number generator functions produce one value at each observation. It is important to use a different seed value for all the random number generator functions in the model program; otherwise, the perturbations will be correlated. For the unperturbed solution, _REP_=0, the random number generator functions return 0.
PROC UNIVARIATE can be used to create confidence intervals for the simulation (see the Monte Carlo simulation example in the "Getting Started" section).
A simple one-dimensional quasi-random sequence is the van der Corput sequence. Given a prime number r ( r>=2 ) any integer has a unique representation in terms of base r. A number in the interval [0,1) can be created by inverting the represention base power by base power. For example, consider r=3 and n=1. 1 in base 3 is
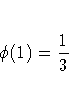
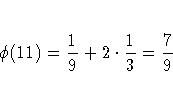
As the sequence proceeds it fills in the gaps in a uniform fashion.
Several authors have expanded this idea to many dimensions. Two versions supported by the MODEL procedure are the Sobol sequence (QUASI=SOBOL) and the Faure sequence (QUASI=FAURE). The Sobol sequence is based on binary numbers an is generally computationaly faster than the Faure sequence. The Faure sequence uses the dimensionality of the problem to determine the number base to use to generate the sequence. The Faure sequence has better distributional properties than the Sobol sequence for dimensions greater than 8.
As an example of the difference between a pseudo random number and a quasi random number consider simulating a bivariate normal with 100 draws.
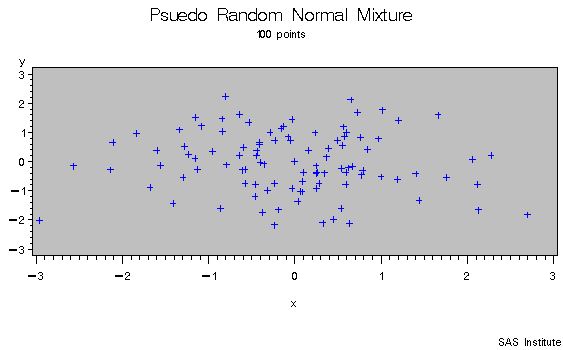
|
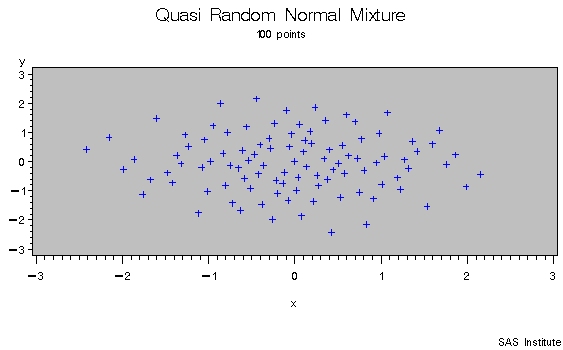
|
proc model data=sashelp.citimon;
parameters a 0.010708 b -0.478849 c 0.929304;
lhur = 1/(a * ip) + b + c * lag(lhur);
solve lhur / out=sim forecast dynamic;
run;
The first page of output produced by the SOLVE
step is shown in Figure 14.63. This is the
summary description of the model. The error message
states that the simulation was aborted at observation
144 because of missing input values.
|
| |||||||||||||||||||||||||||||||
The second page of output, shown in Figure 14.64, gives more information on the failed observation.
|
|
From the program data vector you can see the variable IP is missing for observation 144. LHUR could not be computed so the simulation aborted.
The solution summary table is shown in Figure 14.65.
|
| ||||||||||||||||||||||||||||||||||||||||||
This solution summary table includes the names of the input data set and the output data set followed by a description of the model. The table also indicates the solution method defaulted to Newton's method. The remaining output is defined as follows:
| Maximum CC | is the maximum convergence value accepted by the Newton |
| procedure. This number is always less than the value | |
| for "CONVERGE=." | |
| Maximum Iterations | is the maximum number of Newton iterations performed |
| at each observation and each replication of Monte | |
| Carlo simulations. | |
| Total Iterations | is the sum of the number of iterations required for each |
| observation and each Monte Carlo simulation. | |
| Average Iterations | is the average number of Newton iterations required to |
| solve the system at each step. | |
| Solved | is the number of observations used times the number of |
| random replications selected plus one, for Monte Carlo | |
| simulations. The one additional simulation is the original | |
| unperturbed solution. For simulations not involving Monte | |
| Carlo, this number is the number of observations used. |
proc model data=sashelp.citimon;
parameters a 0.010708 b -0.478849 c 0.929304;
lhur= 1/(a * ip) + b + c * lag(lhur) ;
solve lhur / out=sim dynamic stats theil;
range date to '01nov91'd;
run;
the STATS output in Figure 14.66 and the THEIL
output in Figure 14.67 are generated.
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The number of observations (Nobs), the number of observations with both predicted and actual values nonmissing (N), and the mean and standard deviation of the actual and predicted values of the determined variables are printed first. The next set of columns in the output are defined as follows:
| Mean Error | |
| Mean % Error | |
| Mean Abs Error | |
| Mean Abs % Error | |
| RMS Error | 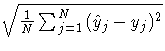 |
| RMS % Error | 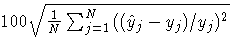 |
| R-square | 1 - SSE / CSSA |
| SSE | |
| SSA | |
| CSSA | 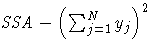 |
| predicted value | |
| y | actual value |
When the RANDOM= option is specified, the statistics do not include the unperturbed (_REP_=0) solution.
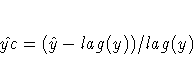
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The columns have the following meaning:
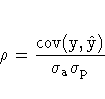
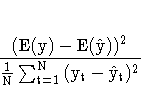
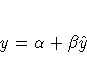
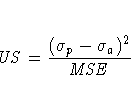
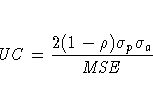
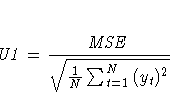
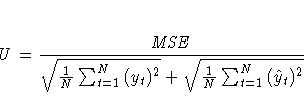
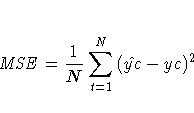
More information on these statistics can be found in the references Maddala (1977, 344--347) and Pindyck and Rubinfeld (1981, 364 -365).
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.