Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| Introduction to Optimization |
Model generation and maintainence are often difficult and expensive aspects of applying mathematical programming techniques. The flexible input formats for the optimization procedures in SAS/OR software simplify this task.
A small product mix problem serves as a starting point for a discussion of different types of model formats supported in SAS/OR software.
A candy manufacturer makes two products: chocolates and toffee. What combination of chocolates and toffee should be produced in a day in order to maximize the company's profit? Chocolates contribute $0.25 per pound to profit and toffee contributes $0.75 per pound. The variables chocolates and toffee are the decision variables.
Four processes are used to manufacture the candy:
Firm time standards have been established for each process. For Process 1, mixing and cooking take 15 seconds for each pound of chocolate and 40 seconds for each pound of toffee. Process 2 takes 56.25 seconds per pound of toffee. For Process 3, 18.75 seconds are required for each pound of chocolate. In packaging, a pound of chocolates can be wrapped in 12 seconds, whereas 50 seconds are required for a pound of toffee. These data are summarized below:
Available Required per Pound
Time chocolates toffee
Process (sec) (sec) (sec)
1 Cooking 27,000 15 40
2 Color/Flavor 27,000 56.25
3 Condiments 27,000 18.75
4 Packaging 27,000 126 50
The object is to
This linear program illustrates the type of problem known as a product mix example. The mix of products that maximizes the objective without violating the constraints is the solution. There are two formats that can represent this model.
data factory;
input _id_ $ CHOCO TOFFEE _type_ $ _rhs_;
datalines;
object 0.25 0.75 MAX .
process1 15.00 40.00 LE 27000
process2 0.00 56.25 LE 27000
process3 18.75 0.00 LE 27000
process4 12.00 50.00 LE 27000
;
To solve this using the Interior Point algorithm of PROC NETFLOW, specify:
proc netflow arcdata=factory condata=factory;However, this example will be solved by the LP procedure. Because the special variables _id_, _type_, and _rhs_ are used in the problem data set, there is no need to identify them to the LP procedure.
proc lp;
The output from the LP procedure is in four sections.
The Problem Summary shows, for example, that there are 2 nonnegative decision variables, namely CHOCO and TOFFEE. It also shows that there are 4 constraints of type LE.
After the procedure displays this information, it solves the problem, then produces the SOLUTION SUMMARY.
When PROC LP solves a problem, an iterative process is used. First, the procedure finds a feasible solution, one that satisfies the constraints. The second phase finds the optimum solution from the set of feasible solutions. The SOLUTION SUMMARY gives the number of iterations the procedure took in each of these phases, the number of variables in the initial feasible solution, the time the procedure used to solve the problem, and the number of matrix inversions necessary.
|
| |||||||||||||||||||||||||||||||||||||||||
After performing 3 phase 2 iterations, the procedure terminated successfully finding an optimum with optimal objective value of 475.
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The VARIABLE SUMMARY contains details about each variable in the solution. The Activity column shows that optimum profitability is achieved when 1000 pounds of chocolate and 300 pounds of toffee are produced. The variables process1, process2, process3, and process4 correspond to the four slack variables in the Process 1, Process 2, Process 3, and Process 4 constraints, respectively. Producing 1000 pounds of chocolate and 300 pounds of toffee a day leaves 10,125 seconds of slack time in Process 2 (where colors and flavors are added to the toffee) and 8,250 seconds of slack time in Process 3 (where nuts and raisins are mixed and added to the chocolate).
The ACTIVITY column gives the value of the right-hand side of each equation when the problem is solved using the information given in the previous table.
The DUAL ACTIVITY column reveals that each second in Process 1 (mixing-cooking) is worth approximately $.013, and each second in Process 4 (Packaging), is worth approximately $.005. These figures (called shadow prices) can be used to decide whether the total available time for Processes 1 and 4 should be increased. If a second can be added to the total production time in Processes 1 for less than $.013, it would be profitable to do so. The dual activities for Process 1 and 4 are zero since adding time to those processes does not increase profits. Keep in mind that the dual activity gives the marginal improvement to the objective and that adding time to Process 1 changes the original problem and solution.
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||
For a complete description of the output from PROC LP, see the chapter on teh LP procedure.
Although the factory example of the last section is not sparse, illustrated here is an example of the sparse input format. The sparse data set has four variables: a row type identifying variable, a row name variable, a column name variable, and a coefficient variable.
data factory;
format _type_ $8. _row_ $16. _col_ $16.;
input _type_ $_row_ $ _col_ $ _coef_ ;
datalines;
max object . .
. object chocolate .25
. object toffee .75
le process1 . .
. process1 chocolate 15
. process1 toffee 40
. process1 _RHS_ 27000
le process2 . .
. process2 toffee 56.25
. process2 _RHS_ 27000
le process3 . .
. process3 chocolate 18.75
. process3 _RHS_ 27000
le process4 . .
. process4 chocolate 12
. process4 toffee 50
. process4 _RHS_ 27000
;
To solve this problem using the Interior Point algorithm of PROC NETFLOW, specify
proc netflow sparsecondata arcdata=factory condata=factory;However, this example will be solved by the LP procedure.
Notice that the _type_ variable contains keywords as for the dense format, the _row_ variable contains the row names in the model, the _col_ variable contains the column names in the model, and the _coef_ variable contains the coefficients for that particular row and column. Since the row and column names are the values of variables in a SAS data set, they are not limited to 8 characters. This feature, as well as the order independence of the format, simplify matrix generation.
The SPARSEDATA option in the PROC LP statement tells the LP procedure that the model in the problem data set is in the sparse format. This example also illustrates how the solution of the linear program is saved in two output data sets: the primal data set and the dual data set.
proc lp
data=factory sparsedata
primalout=primal dualout=dual;
run;
The primal data set (Figure 1.12) contains the information that is displayed in the VARIABLE SUMMARY plus additional information about the bounds on the variables.
|
|
The dual data set (Figure 1.13) contains the information that is displayed in the CONSTRAINT SUMMARY plus additional information about bounds on the rows.
|
|
|
Suppose the candy manufacturing company has two factories, two warehouses, and three customers for chocolate. The two factories each have a production capacity of 500 pounds per day. The three customers have demands of 100, 200, and 50 pounds per day, respectively.
The following data set describes the supplies (positive values for the supdem variable) and the demands (negative values for the supdem variable) for each of the customers and factories.
data nodes;
format node $16. ;
input node $ supdem;
datalines;
customer_1 -100
customer_2 -200
customer_3 -50
factory_1 500
factory_2 500
;
Suppose that there are two warehouses that are used to store the chocolate before shipment to the customers and that there are different costs for shipping between each factory, warehouse, and customer.
What is the minimum cost routing for supplying the customers?
Arcs are described in another data set. Each observation defines a new arc in the network and gives data about the arc. For example, there is an arc between the node factory_1 and the node warehouse_1. Each unit of flow on that arc costs 10. Although this example does not include it, lower and upper bounds on the flow across that arc can be listed here.
data network;
format from $16. to $16.;
input from $ to $ cost ;
datalines;
factory_1 warehouse_1 10
factory_2 warehouse_1 5
factory_1 warehouse_2 7
factory_2 warehouse_2 9
warehouse_1 customer_1 3
warehouse_1 customer_2 4
warehouse_1 customer_3 4
warehouse_2 customer_1 5
warehouse_2 customer_2 5
warehouse_2 customer_3 6
;
Use PROC NETFLOW to find the minimum cost routing. This procedure takes the model as defined in the network and nodes data sets and finds the minimum cost flow.
proc netflow arcout=arc_sav
arcdata=network nodedata=nodes;
node node; /* node data set information */
supdem supdem;
tail from; /* arc data set information */
head to;
cost cost;
run;
proc print;
var from to cost _capac_ _lo_ _supply_ _demand_
_flow_ _fcost_ _rcost_;
sum _fcost_;
run;
PROC NETFLOW produces the following on the SAS log:
NOTE: Number of nodes= 7 . NOTE: Number of supply nodes= 2 . NOTE: Number of demand nodes= 3 . NOTE: Total supply= 1000 , total demand= 350 . NOTE: Number of arcs= 10 . NOTE: Number of iterations performed (neglecting any constraints)= 7 . NOTE: Of these, 2 were degenerate. NOTE: Optimum (neglecting any constraints) found. NOTE: Minimal total cost= 3050 . NOTE: The data set WORK.ARC_SAV has 10 observations and 13 variables.
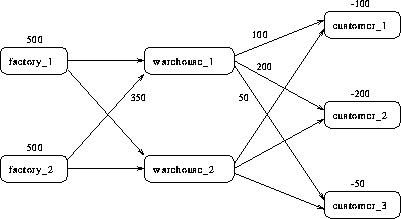
The solution (Figure 1.15) saved in the arc_sav data set shows the optimal amount of chocolate to send across each arc (the amount to ship from each factory to each warehouse and from each warehouse to each customer) in the network per day.
|
|
Notice which arcs have positive flow (_FLOW_ is greater than 0). These arcs indicate the amount of chocolate that should be sent from factory_2 to warehouse_1 and from there on to the three customers. The model indicates no production at factory_1 and no use of warehouse_2.
|
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.