Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| The NLP Procedure |
PROC NLP solves
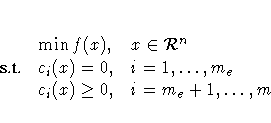
where f is the objective function and the m ci's are the constraint functions.
A point x is feasible if it satisfies all the constraints. The feasible region G is the set of all the feasible points. x* is a global solution of the preceeding problem if no point in G has a lower function value than f(x*). x* is a local solution of the problem if there exists some open neighborhood surrounding x* in that no point has a lower function value than f(x*). Nonlinear Programming algorithms cannot consistently find global minima. All the algorithms in PROC NLP find a local minimum for this problem. If you need to check whether the obtained solution is a global minimum, you may have to run PROC NLP with different starting points obtained either at random or by selecting a point on a grid that contains G.
The local minimizer x* of this problem satisfies the following local optimality conditions:
Most of the optimization algorithms in PROC NLP use iterative techniques that result in a sequence of points x0,...,xn,..., that converges to a local solution x*. At the solution, PROC NLP performs tests to confirm that the (projected) gradient is close to zero and that the (projected) Hessian matrix is positive definite.
An important tool in the analysis and design of algorithms in constrained optimization is the Lagrangian Function, that is a linear combination of the objective function and the constraints:
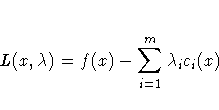
The coefficients ![]() are called Lagrange multipliers.
This tool makes it possible to state necessary and sufficient
conditions for a local minimum. The various algorithms in PROC NLP
create sequences of points, each of that is closer than the previous
one to satisfying these conditions.
are called Lagrange multipliers.
This tool makes it possible to state necessary and sufficient
conditions for a local minimum. The various algorithms in PROC NLP
create sequences of points, each of that is closer than the previous
one to satisfying these conditions.
Assuming that the functions f and ci are twice continuously
differentiable, the point x* is a local
minimum of the nonlinear programming problem, if there exists a vector
![]() that meets the following
conditions.
that meets the following
conditions.
1. first-order, Karush-Kuhn-Tucker conditions:
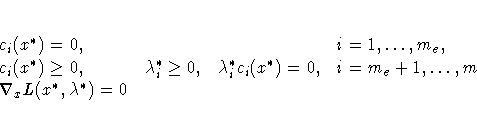
2. Second-order conditions:
Each nonzero vector ![]() for which
for which
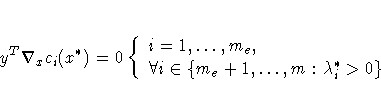
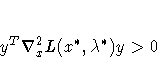
Most of the algorithms to solve this problem attempt to find a
combination of vectors x and ![]() for which the gradient
of the Langrangian function in respect to x is zero.
for which the gradient
of the Langrangian function in respect to x is zero.
The gradient vector contains the first derivatives of the objective function f with respect to the parameters x1, ... ,xn, as follows:
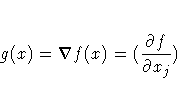
The n ×n symmetric Hessian matrix contains the second derivatives of the objective function f with respect to the parameters x1, ... ,xn, as follows:
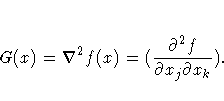
For Least-Squares problems, the m ×n Jacobian matrix contains the first-order derivatives of m objective functions fi(x) with respect to the parameters x1, ... ,xn, as follows:
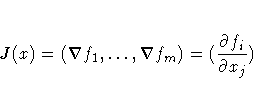
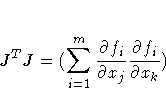
The mc ×n Jacobian matrix contains the first-order derivatives of mc nonlinear constraint functions ci(x), i = 1, ... ,mc, with respect to the parameters x1, ... ,xn, as follows:
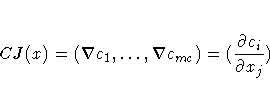
PROC NLP provides three ways to compute derivatives:
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.