Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| The RELIABILITY Procedure |
You can use the RELIABILITY procedure to construct probability plots for data that are complete, right censored, or interval censored (in readout form) for each of the probability distributions in Table 30.37.
A random variable Y belongs to a location-scale family of distributions if its CDF F is of the form
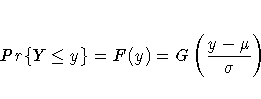
where ![]() is
the location parameter, and
is
the location parameter, and ![]() is the scale parameter.
Here, G is a CDF
that cannot depend on any unknown parameters, and G is the CDF
of Y if
is the scale parameter.
Here, G is a CDF
that cannot depend on any unknown parameters, and G is the CDF
of Y if ![]() and
and ![]() .
For example, if Y is a normal random variable with mean
.
For example, if Y is a normal random variable with mean ![]() and
standard deviation
and
standard deviation ![]() ,
,
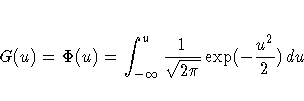
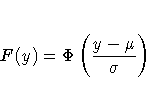
Of the distributions in Table 30.37, the normal, extreme value, and logistic distributions are location-scale models. As shown in Table 30.38, if T has a lognormal, Weibull, or log-logistic distribution, then log(T) has a distribution that is a location-scale model. Probability plots are constructed for lognormal, Weibull, and log-logistic distributions by using log(T) instead of T in the plots.
Let ![]() be ordered
observations of a random sample with distribution function
F(y).
A probability plot is a plot of the points y(i) against
mi=G-1(ai), where
be ordered
observations of a random sample with distribution function
F(y).
A probability plot is a plot of the points y(i) against
mi=G-1(ai), where
![]() is an estimate of the CDF
is an estimate of the CDF
![]() .The points ai are called plotting positions. The axis on
which the points mis are plotted is usually labeled with a probability
scale (the scale of ai).
.The points ai are called plotting positions. The axis on
which the points mis are plotted is usually labeled with a probability
scale (the scale of ai).
If F is one of the location-scale distributions, then y is the lifetime; otherwise, the log of the lifetime is used to transform the distribution to a location-scale model.
If the data actually
have the stated distribution, then ![]() ,
,
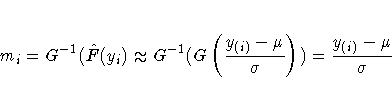
There are several ways to compute plotting positions from failure data. These are discussed in the next two sections.
For the Kaplan-Meier method,
For the modified Kaplan-Meier method, use
For complete samples, ai=i/(n+1) for the expected rank method, a'i=i/n for the Kaplan-Meier method, and a''i=(i-.5)/n for the modified Kaplan-Meier method. If the largest observation is a failure for the Kaplan-Meier estimator, then Fn=1 and the point is not plotted. These three methods are shown for the field winding data in Table 30.40 and Table 30.41.
Table 30.40: Expected Rank Plotting Position Calculations
| Ordered | Reverse | ri/(ri+1) | ×Ri-1 | =Ri | ai=1-Ri |
| Observation | Rank | ||||
| 31.7 | 16 | 16/17 | 1.0000 | 0.9411 | 0.0588 |
| 39.2 | 15 | 15/16 | 0.9411 | 0.8824 | 0.1176 |
| 57.5 | 14 | 14/15 | 0.8824 | 0.8235 | 0.1765 |
| 65.0+ | 13 | ||||
| 65.8 | 12 | 12/13 | 0.8235 | 0.7602 | 0.2398 |
| 70.0 | 11 | 11/12 | 0.7602 | 0.6968 | 0.3032 |
| 75.0+ | 10 | ||||
| 75.0+ | 9 | ||||
| 87.5+ | 8 | ||||
| 88.3+ | 7 | ||||
| 94.2+ | 6 | ||||
| 101.7+ | 5 | ||||
| 105.8 | 4 | 4/5 | 0.6968 | 0.5575 | 0.4425 |
| 109.2+ | 3 | ||||
| 110.0 | 2 | 2/3 | 0.5575 | 0.3716 | 0.6284 |
| 130.0+ | 1 | ||||
| + Censored Times | |||||
| Ordered | Reverse | (ri-1)/ri | ×Ri-1 | =Ri | a'i=1-Ri | a''i |
| Observation | Rank | |||||
| 31.7 | 16 | 15/16 | 1.0000 | 0.9375 | 0.0625 | 0.0313 |
| 39.2 | 15 | 14/15 | 0.9375 | 0.8750 | 0.1250 | 0.0938 |
| 57.5 | 14 | 13/14 | 0.8750 | 0.8125 | 0.1875 | 0.1563 |
| 65.0+ | 13 | |||||
| 65.8 | 12 | 11/12 | 0.8125 | 0.7448 | 0.2552 | 0.2214 |
| 70.0 | 11 | 10/11 | 0.7448 | 0.6771 | 0.3229 | 0.2891 |
| 75.0+ | 10 | |||||
| 75.0+ | 9 | |||||
| 87.5+ | 8 | |||||
| 88.3+ | 7 | |||||
| 94.2+ | 6 | |||||
| 101.7+ | 5 | |||||
| 105.8 | 4 | 3/4 | 0.6771 | 0.5078 | 0.4922 | 0.4076 |
| 109.2+ | 3 | |||||
| 110.0 | 2 | 1/2 | 0.5078 | 0.2539 | 0.7461 | 0.6192 |
| 130.0+ | 1 | |||||
| + Censored Times | ||||||
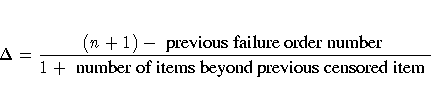
For complete data, an alternative method of computing the median rank plotting position for failure i is to compute the exact median of the distribution of the ith order statistic of a sample of size n from the uniform distribution on (0,1). If the data are right censored, the adjusted rank ji, as defined in the preceding paragraph, is used in place of i in the computation of the median rank. The PPOS=MEDRANK1 option specifies this type of plotting position.
Nelson (1982, p.148) provides the following example of multiply right-censored failure data for field windings in electrical generators. Table 30.42 shows the data, the intermediate calculations, and the plotting positions calculated by exact (a'i) and approximate (ai) median ranks.
Table 30.42: Median Rank Plotting Position Calculations| Ordered | Increment | Failure Order | ||
| Observation |
|
Number ji | ai | a'i |
| 31.7 | 1.0000 | 1.0000 | 0.04268 | 0.04240 |
| 39.2 | 1.0000 | 2.0000 | 0.1037 | 0.1027 |
| 57.5 | 1.0000 | 3.0000 | 0.1646 | 0.1637 |
| 65.0+ | 1.0769 | |||
| 65.8 | 1.0769 | 4.0769 | 0.2303 | 0.2294 |
| 70.0 | 1.0769 | 5.1538 | 0.2960 | 0.2953 |
| 75.0+ | 1.1846 | |||
| 75.0+ | 1.3162 | |||
| 87.5+ | 1.4808 | |||
| 88.3+ | 1.6923 | |||
| 94.2+ | 1.9744 | |||
| 101.7+ | 2.3692 | |||
| 105.8 | 2.3692 | 7.5231 | 0.4404 | 0.4402 |
| 109.2+ | 3.1590 | |||
| 110.0 | 3.1590 | 10.6821 | 0.6331 | 0.6335 |
| 130.0+ | 6.3179 | |||
| + Censored Times | ||||
Note that there is right censoring as well as interval censoring in these data. For example, two units fail in the interval (24, 48) hours, and there are 1414 unfailed units at the beginning of the interval, 24 hours. At the beginning of the next interval, (48, 168) hours, there are 573 unfailed units. The number of unfailed units that are removed from the test at 48 hours is 1414 - 2 - 573 = 839 units. These are right-censored units.
The reliability at the end of interval i is computed recursively as
| Interval | Interval | fi/ni | R'i= | Ri= | ai=1-Ri |
| i | Endpoint ti | 1-(fi/ni) | R'iRi-1 | ||
| 1 | 6 | 6/1423 | 0.99578 | 0.99578 | .00421 |
| 2 | 12 | 2/1417 | 0.99859 | 0.99438 | .00562 |
| 3 | 24 | 0/1415 | 1.00000 | 0.99438 | .00562 |
| 4 | 48 | 2/1414 | 0.99859 | 0.99297 | .00703 |
| 5 | 168 | 1/573 | 0.99825 | 0.99124 | .00876 |
| 6 | 500 | 1/422 | 0.99763 | 0.98889 | .01111 |
| 7 | 1000 | 2/272 | 0.99265 | 0.98162 | .01838 |
| 8 | 2000 | 1/123 | 0.99187 | 0.97364 | .02636 |
The variance v(ai) of the cumulative probability estimate ai=1-Ri is computed using the exact variance method of Nelson (1990 pp. 150-151).
If no right censoring has occurred before ti, then ai is a binomial probability, and exact binomial confidence limits for ai are computed. See Binomial Distribution for a description of this method.
If right censoring has occurred before ti, then
two-sided approximate ![]() confidence limits for ai
are computed as
confidence limits for ai
are computed as
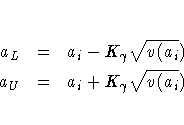
The estimates ai, confidence limits aL and aU,
and standard errors ![]() are
tabulated in the ANALYZE, PROBPLOT,
and RELATIONPLOT statements for readout data. The PCONFPLT
option requests that the confidence limits be displayed on probability plots.
are
tabulated in the ANALYZE, PROBPLOT,
and RELATIONPLOT statements for readout data. The PCONFPLT
option requests that the confidence limits be displayed on probability plots.
Although this method applies to more general situations, where the intervals may be overlapping, the example of the previous section will be used to illustrate the method. Table 30.44 contains the microprocessor data of the previous section, arranged in intervals. A missing (.) lower endpoint indicates left censoring, and a missing upper endpoint indicates right censoring. These can be thought of as semi-infinite intervals with lower (upper) endpoint of negative (positive) infinity for left (right) censoring.
Table 30.44: Interval-Censored Data| Lower | Upper | Number |
| Endpoint | Endpoint | Failed |
| . | 6 | 6 |
| 6 | 12 | 2 |
| 24 | 48 | 2 |
| 24 | . | 1 |
| 48 | 168 | 1 |
| 48 | . | 839 |
| 168 | 500 | 1 |
| 168 | . | 150 |
| 500 | 1000 | 2 |
| 500 | . | 149 |
| 1000 | 2000 | 1 |
| 1000 | . | 147 |
| 2000 | . | 122 |
The following SAS program will compute the Turnbull estimate and create a lognormal probability plot.
data micro;
input t1 t2 f ;
datalines;
. 6 6
6 12 2
12 24 0
24 48 2
24 . 1
48 168 1
48 . 839
168 500 1
168 . 150
500 1000 2
500 . 149
1000 2000 1
1000 . 147
2000 . 122
;
proc reliability data=micro;
distribution lognormal;
freq f;
pplot ( t1 t2 ) / itprintem
printprobs
maxitem = (1000,25)
nofit
pconfplt
ppout
cframe = ligr;
inset / cfill = ywh;
run;
The nonparametric maximum likelihood estimate of the CDF can only increase on certain intervals, and must remain constant between the intervals. The Turnbull algorithm first computes the intervals on which the nonparametric maximum likelihood estimate of the CDF can increase. The algorithm then iteratively estimates the probability associated with each interval. The ITPRINTEM option along with the PRINTPROBS option instructs the procedure to print the intervals on which probability increases can occur and the iterative history of the estimates of the interval probabilities. The PPOUT option requests tabular output of the estimated CDF, standard errors, and confidence limits for each cumulative probability.
Figure 30.25 shows every 25th iteration and the last iteration for the Turnbull estimate of the CDF for the microprocessor data. The initial estimate assigns equal probabilities to each interval. You can specify different initial values with the PROBLIST= option. The algorithm converges in 130 iterations for this data. Convergence is determined if the change in the log-likelihood between two successive iterations less than delta, where the default value of delta is 10-8. You can specify a different value for delta with the TOLLIKE= option. This algorithm is an example of an expectation-maximization (EM) algorithm. EM algorithms are known to converge slowly, but the computations within each iteration for the Turnbull algorithm are moderate. Iterations will be terminated if the algorithm does not converge after a fixed number of iterations. The default maximum number of iterations is 1000. Some data may require more iterations for convergence. You can spoecify the maximum allowed number of iterations with the MAXITEM= option in the PROBPLOT, ANALYZE, or RPLOT statements.
If an interval probability is smaller than a tolerance (10-6 by default) after convergence, the probability is set to zero, the interval probabilities are renormalized so that they add to one, and iterations are restarted. Usually the algorithm converges in just a few more iterations. You can change the default value of the tolerance with the TOLPROB= option. You can specify the NOPOLISH option to avoid setting small probabilities to zero and restarting the algorithm.
If you specify the ITPRINTEM option, the table in Figure 30.26 summarizing the Turnbull estimate of the interval probabilities is printed. The columns labeled 'Reduced Gradient' and 'Lagrange Multiplier' are used in checking final convergence to the maximum likelihood estimate. The Lagrange multipliers must all be greater than or equal to zero, or the solution is not maximum likelihood. Refer to Gentleman and Geyer (1994) for more details of the convergence checking.
|
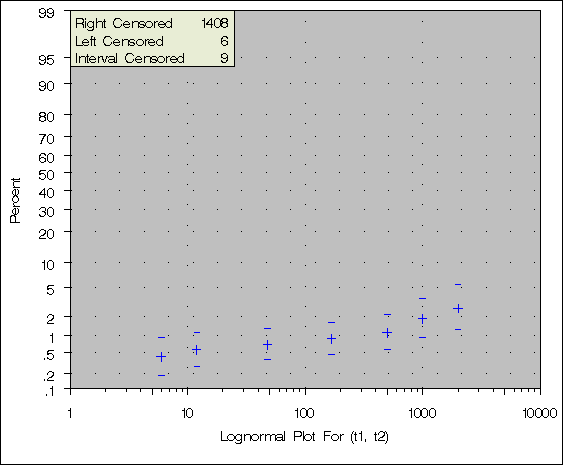
Figure 30.27 shows the final estimate of the CDF, along with standard errors and confidence limits. Figure 30.28 shows the CDF and pointwise confidence limits plotted on a lognormal probability plot.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.