| Introduction to
Regression Procedures |
Linear Models
In matrix algebra notation, a linear model is written as
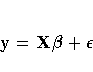
where X is the n ×k design
matrix (rows are observations and columns are the
regressors), 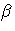 is the k ×1
vector of unknown parameters, and
is the k ×1
vector of unknown parameters, and 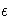 is the n ×1 vector of unknown errors.
The first column of X is usually a vector
of 1s used in estimating the intercept term.
is the n ×1 vector of unknown errors.
The first column of X is usually a vector
of 1s used in estimating the intercept term.
The statistical theory of linear models
is based on strict classical assumptions.
Ideally, the response is measured with all the factors
controlled in an experimentally determined environment.
If you cannot control the factors experimentally,
some tests must be interpreted as being conditional
on the observed values of the regressors.
Other assumptions are that
- the form of the model is correct (all important
explanatory variables have been included)
- regressor variables are measured without error
- the expected value of the errors is zero
- the variance of the errors (and thus the dependent variable)
is a constant across observations (called
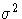 )
) - the errors are uncorrelated across observations
When hypotheses are tested, the
additional assumption is made that
the errors are normally distributed.
Statistical Model
If the model satisfies all the necessary
assumptions, the least-squares estimates are
the best linear unbiased estimates (BLUE).
In other words, the estimates have minimum
variance among the class of estimators that are
unbiased and are linear functions of the responses.
If the additional assumption that the error term
is normally distributed is also satisfied, then
- the statistics that are computed have the proper
sampling distributions for hypothesis testing
- parameter estimates are normally distributed
- various sums of squares are distributed proportional
to chi-square, at least under proper hypotheses
- ratios of estimates to standard errors are
distributed as Student's t under certain hypotheses
- appropriate ratios of sums of squares are
distributed as F under certain hypotheses
When regression analysis is used to model data that
do not meet the assumptions, the results should
be interpreted in a cautious, exploratory fashion.
The significance probabilities under
these circumstances are unreliable.
Box (1966) and Mosteller and Tukey (1977, chaps. 12 and 13)
discuss the problems that are encountered with regression data,
especially when the data are not under experimental control.
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.