Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| The MIXED Procedure |
The following sections describe the output PROC MIXED produces by default. This output is organized into various tables, and they are discussed in order of appearance.
The "Model Information" table also has a row labeled Fixed Effects SE Method. This row describes the method used to compute the approximate standard errors for the fixed-effects parameter estimates and related functions of them. The two possibilities for this row are Model-Based, which is the default method, and Empirical, which results from using the EMPIRICAL option in the PROC MIXED statement.
For ODS purposes, the label of the "Model Information" table is "ModelInfo."
The Evaluations column of the "Iteration History" table tells how many times the objective function is evaluated during each iteration.
The Criterion column of the "Iteration History" table is, by default, a relative Hessian convergence quantity given by
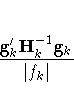
where fk is the value of the objective function at iteration k, gk is the gradient (first derivative) of fk, and Hk is the Hessian (second derivative) of fk. If Hk is singular, then PROC MIXED uses the following relative quantity:
To prevent the division by |fk|, use the ABSOLUTE option in the PROC MIXED statement. To use a relative function or gradient criterion, use the CONVF or CONVG options, respectively. The Hessian criterion is considered superior to function and gradient criteria because it measures orthogonality rather than lack of progress (Bates and Watts 1988). Provided the initial estimate is feasible and the maximum number of iterations is not exceeded, the Newton-Raphson algorithm is considered to have converged when the criterion is less than the tolerance specified with the CONVF, CONVG, or CONVH option in the PROC MIXED statement. The default tolerance is 1E-8. If convergence is not achieved, PROC MIXED displays the estimates of the parameters at the last iteration.
A convergence criterion that is missing indicates that a boundary constraint has been dropped; it is usually not a cause for concern.
If you specify the ITDETAILS option in the PROC MIXED statement, then the covariance parameter estimates at each iteration are included as additional columns in the "Iteration History" table.
For ODS purposes, the label of the "Iteration History" table is "IterHistory."
If you specify the RATIO option in the PROC MIXED statement, the Ratio column is added to the table listing the ratios of each parameter estimate to that of the residual variance.
Requesting the COVTEST option in the PROC MIXED statement produces the Std Error, Z Value, and Pr > |Z| columns. The Std Error column contains the approximate standard errors of the covariance parameter estimates. These are the square roots of the diagonal elements of the observed inverse Fisher information matrix, which equals 2H-1, where H is the Hessian matrix. The H matrix consists of the second derivatives of the objective function with respect to the covariance parameters; refer to Wolfinger, Tobias, and Sall (1994) for formulas. When you use the SCORING= option and PROC MIXED converges without stopping the scoring algorithm, PROC MIXED uses the expected Hessian matrix to compute the covariance matrix instead of the observed Hessian. The observed or expected inverse Fisher information matrix can be viewed as an asymptotic covariance matrix of the estimates.
The Z Value column is the estimate divided by its approximate standard error, and the Pr > |Z| column is the two-tailed area of the standard Gaussian density outside of the Z-value. These statistics constitute Wald tests of the covariance parameters, and they are valid only asymptotically.
Caution: Wald tests can be unreliable in small samples.
For ODS purposes, the label of the "Covariance Parameter Estimates" table is "CovParms."
Akaike's Information Criterion (AIC) (Akaike 1974) is computed as
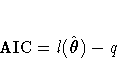
Schwarz's Bayesian Criterion (BIC) (Schwarz 1978) is computed as
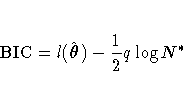
The IC option in the PROC MIXED statement produces an "Information Criteria" table of these criteria and two others in a variety of different forms.
For ODS purposes, the label of the "Model Fitting Information" table is "FitStatistics."
This test is reported in the "Null Model Likelihood Ratio
Test" table to determine whether it is necessary to model the
covariance structure of the data at all. The "Chi-Square"
value is -2 times the log likelihood from the null model minus
-2 times the log likelihood from the fitted model, where the null
model is the one with only the fixed effects listed in the MODEL
statement and ![]() . This statistic has an
asymptotic
. This statistic has an
asymptotic ![]() -distribution with q-1 degrees of freedom,
where q is the effective number of covariance parameters
(those not estimated to be on a boundary constraint). The
Pr > ChiSq column contains the upper-tail area from this distribution. This
p-value can be used to assess the significance of the model fit.
-distribution with q-1 degrees of freedom,
where q is the effective number of covariance parameters
(those not estimated to be on a boundary constraint). The
Pr > ChiSq column contains the upper-tail area from this distribution. This
p-value can be used to assess the significance of the model fit.
This test is not produced for cases where the null hypothesis lies on the boundary of the parameter space, which is typically for variance component models. This is because the standard asymptotic theory does not apply in this case (Self and Liang 1987, Case 5).
If you specify a PARMS statement, PROC MIXED constructs a likelihood ratio test between the best model from the grid search and the final fitted model and reports the results in the "Parameter Search" table.
For ODS purposes, the label of the "Null Model Likelihood Ratio Test" table is "LRT."
![F = \frac{ \hat{{\beta}}'L'
[L(X'\hat{V}^{-1}X)^-L']^{-}
{L\hat{{\beta}}}}
{{\rm rank}(L)}](images/mixeq199.gif)
You can use the CHISQ option in the MODEL statement to obtain Wald
![]() tests of the fixed effects. These are carried out by using
the numerator of the F-statistic and comparing it with the
tests of the fixed effects. These are carried out by using
the numerator of the F-statistic and comparing it with the
![]() distribution with NDF degrees of freedom. It is more
liberal than the F-test because it effectively assumes an
infinite denominator degrees of freedom.
distribution with NDF degrees of freedom. It is more
liberal than the F-test because it effectively assumes an
infinite denominator degrees of freedom.
For ODS purposes, the label of the "Type 1 Tests of Fixed Effects" through the "Type 3 Tests of Fixed Effects" tables are "Tests1" through "Tests3," respectively.
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.