![]()
![]()
![]()
Reading for Today's Lecture: Chapter 4 sections 1-3.
Goals of Today's Lecture:
Look at the matrix product
![]() :
:
![\begin{displaymath}\left[\begin{array}{ll} \frac{3}{5} & \frac{2}{5}
\\
\frac{1...
... \frac{2}{5}
\\
\frac{1}{5} & \frac{4}{5}
\end{array} \right]
\end{displaymath}](img3.gif)
General case. Define
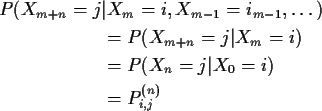
Proof of these assertions by induction on m,n.
Example for n=2. Two bits to do:
First suppose U,V,X,Y are discrete variables.
Assume
![]()
for any x,y,u,v. Then I claim
![]()
In words, if knowing both U and V doesn't change the
conditional probability then knowing U alone doesn't
change the conditional probability.
Proof of claim:

Second step: consider
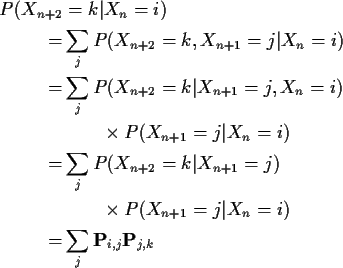
This shows that
More general version
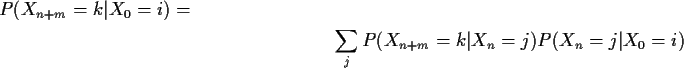
Summary: A Markov Chain has stationary n step transition probabilities which are the nth power of the 1 step transition probabilities.
Here is Maple output for the 1,2,4,8 and 16 step transition matrices for our rainfall example:
> p:= matrix(2,2,[[3/5,2/5],[1/5,4/5]]);
[3/5 2/5]
p := [ ]
[1/5 4/5]
> p2:=evalm(p*p):
> p4:=evalm(p2*p2):
> p8:=evalm(p4*p4):
> p16:=evalm(p8*p8):
This computes the powers (evalm understands
matrix algebra).
Fact:
![\begin{displaymath}\lim_{n\to\infty} {\bf P}^n = \left[
\begin{array}{cc} \frac{...
...{3}
\\
\\
\frac{1}{3} & \frac{2}{3}
\end{array}\right] \, .
\end{displaymath}](img16.gif)
> evalf(evalm(p));
[.6000000000 .4000000000]
[ ]
[.2000000000 .8000000000]
> evalf(evalm(p2));
[.4400000000 .5600000000]
[ ]
[.2800000000 .7200000000]
> evalf(evalm(p4));
[.3504000000 .6496000000]
[ ]
[.3248000000 .6752000000]
> evalf(evalm(p8));
[.3337702400 .6662297600]
[ ]
[.3331148800 .6668851200]
> evalf(evalm(p16));
[.3333336197 .6666663803]
[ ]
[.3333331902 .6666668098]
Where did 1/3 and 2/3 come from?
Suppose we toss a coin
![]() and start the
chain with Dry if we get heads and Wet if we get
tails.
and start the
chain with Dry if we get heads and Wet if we get
tails.
Then


A special ![]() :
if we put
:
if we put
![]() and
and
![]() then
then
![\begin{displaymath}\left[ \frac{1}{3} \quad \frac{2}{3} \right]
\left[\begin{ar...
...y} \right] = \left[ \frac{1}{3} \quad \frac{2}{3} \right] \, .
\end{displaymath}](img23.gif)
A probability vector ![]() is called an initial distribution for
the chain if
is called an initial distribution for
the chain if
A Markov Chain is stationary if
An initial distribution is called stationary if the chain is
stationary. We find that ![]() is a stationary initial distribution
if
is a stationary initial distribution
if
Suppose ![]() converges to some matrix
converges to some matrix
![]() .
Notice that
.
Notice that
![\begin{align*}{\bf P}^\infty & = \lim {\bf P}^n
\\
& = \left[\lim {\bf P}^{n-1}\right] {\bf P}
\\
& = {\bf P}^\infty {\bf P}\, .
\end{align*}](img29.gif)
This proves that each row ![]() of
of
![]() satisfies
satisfies
Def'n: A row vector x is a left eigenvector of A with
eigenvalue ![]() if
if
So each row of
![]() is a left eigenvector of
is a left eigenvector of ![]() with eigenvalue 1.
with eigenvalue 1.