![]()
![]()
![]()
Last names example has following structure: if, at generation
![]() there are
there are ![]() individuals then the number of sons in the
next generation has the distribution of the sum of
individuals then the number of sons in the
next generation has the distribution of the sum of ![]() independent
copies of the random variable
independent
copies of the random variable ![]() which is the number of sons I have.
This distribution does not depend on
which is the number of sons I have.
This distribution does not depend on ![]() , only on the value
, only on the value ![]() of
of ![]() .
We call
.
We call ![]() a Markov Chain.
a Markov Chain.
Ingredients of a Markov Chain:
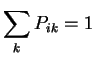 and
and
The stochastic process
![]() is called a
Markov chain if
is called a
Markov chain if
The matrix ![]() is called a transition matrix.
is called a transition matrix.
Example: If ![]() in the last names example has
a Poisson
in the last names example has
a Poisson![]() distribution then given
distribution then given ![]() ,
,
![]() is like sum of
is like sum of ![]() independent Poisson
independent Poisson![]() rvs which has a Poisson(
rvs which has a Poisson(![]() ) distribution.
So
) distribution.
So
![$\displaystyle {\bf P}= \left[\begin{array}{llll}
1 & 0 & 0 & \cdots
\\
e^{-\l...
...\lambda} &
\cdots
\\
\vdots &
\vdots &
\vdots &
\ddots
\end{array}\right]
$](img24.gif)
Example: Weather: each day is dry (D) or wet (W).
![]() is weather on day n.
is weather on day n.
Suppose dry days tend to be followed by dry days, say 3 times in 5 and wet days by wet 4 times in 5.
Markov assumption: yesterday's weather irrelevant to prediction of tomorrow's given today's.
Transition Matrix:
![$\displaystyle {\bf P}= \left[\begin{array}{cc} \frac{3}{5} & \frac{2}{5}
\\
\\
\frac{1}{5} & \frac{4}{5}
\end{array} \right]
$](img26.gif)
Now suppose it's wet today. P(wet in 2 days)?
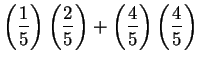 |
![$\displaystyle \left[\begin{array}{ll} \frac{3}{5} & \frac{2}{5}
\\
\\
\frac...
...25} & \frac{14}{25}
\\
\\
\frac{7}{25} & \frac{18}{25}
\end{array} \right]
$](img40.gif)
General case. Define
Proof of these assertions by induction on ![]() .
.
Example for ![]() . Two bits to do:
. Two bits to do:
First suppose ![]() are discrete variables.
Assume
are discrete variables.
Assume
Proof of claim:
 |
||
 |
||
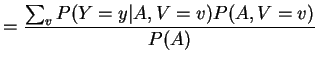 |
||
 |
||
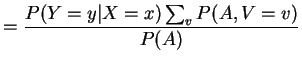 |
||
 |
||
Second step: consider
 |
||
 |
||
 |
||
 |
More general version
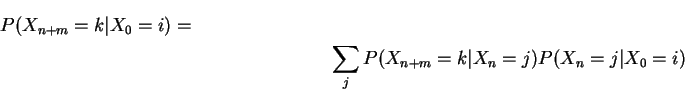
Summary: A Markov Chain has stationary ![]() step transition
probabilities which are the
step transition
probabilities which are the ![]() th power of the 1 step transition
probabilities.
th power of the 1 step transition
probabilities.
Here is Maple output for the 1,2,4,8 and 16 step transition matrices for our rainfall example:
> p:= matrix(2,2,[[3/5,2/5],[1/5,4/5]]);
[3/5 2/5]
p := [ ]
[1/5 4/5]
> p2:=evalm(p*p):
> p4:=evalm(p2*p2):
> p8:=evalm(p4*p4):
> p16:=evalm(p8*p8):
This computes the powers ( evalm understands
matrix algebra).
Fact:
![\begin{displaymath}
\lim_{n\to\infty} {\bf P}^n = \left[
\begin{array}{cc} \frac...
...{2}{3}
\\
\\
\frac{1}{3} & \frac{2}{3}
\end{array}\right]
\end{displaymath}](img80.gif)
> evalf(evalm(p));
[.6000000000 .4000000000]
[ ]
[.2000000000 .8000000000]
> evalf(evalm(p2));
[.4400000000 .5600000000]
[ ]
[.2800000000 .7200000000]
> evalf(evalm(p4));
[.3504000000 .6496000000]
[ ]
[.3248000000 .6752000000]
> evalf(evalm(p8));
[.3337702400 .6662297600]
[ ]
[.3331148800 .6668851200]
> evalf(evalm(p16));
[.3333336197 .6666663803]
[ ]
[.3333331902 .6666668098]
Where did
Suppose we toss a coin
![]() and start the
chain with Dry if we get heads and Wet if we get
tails.
and start the
chain with Dry if we get heads and Wet if we get
tails.
Then

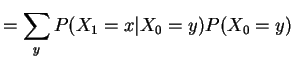 |
||
 |
![$\displaystyle \left[ \frac{1}{3} \quad \frac{2}{3} \right]
\left[\begin{array}{...
...frac{4}{5}
\end{array} \right] = \left[ \frac{1}{3} \quad \frac{2}{3} \right]
$](img91.gif)
A probability vector ![]() is called an initial distribution for
the chain if
is called an initial distribution for
the chain if
A Markov Chain is stationary if
An initial distribution is called stationary if the chain is
stationary. We find that ![]() is a stationary initial distribution
if
is a stationary initial distribution
if
Suppose ![]() converges to some matrix
converges to some matrix
![]() . Notice that
. Notice that
This proves that each row ![]() of
of
![]() satisfies
satisfies
Def'n: A row vector ![]() is a left eigenvector of
is a left eigenvector of ![]() with
eigenvalue
with
eigenvalue ![]() if
if
So each row of
![]() is a left eigenvector of
is a left eigenvector of ![]() with eigenvalue
with eigenvalue ![]() .
.