![]()
![]()
![]()
Reading for Today's Lecture: Sections 1 to 3 of Chapter 4 of Mood, Graybill and Boes.
Goals of Today's Lecture:
Today's notes
Last time: We defined Probability Space
![]() ,
real and Rp valued random variables, cumulative
distribution functions,
,
real and Rp valued random variables, cumulative
distribution functions,
![]() ,
described properties of Ffor p=1 and proved a couple of these facts about F.
,
described properties of Ffor p=1 and proved a couple of these facts about F.
Definition: The distribution of a random variable X is discrete
(we also call the random variable discrete) if there
is a countable set
![]() such that
such that
The distribution of a random variable X is absolutely continuous
if there is a function f such that
Notation: Some students will not be used to the notation
![]() for
a multiple integral. For instance if p=2 and the set A is the disk of radius 1
centered at the origin then
for
a multiple integral. For instance if p=2 and the set A is the disk of radius 1
centered at the origin then

Example: X is exponential.


Example: The function


General Problem: Start with assumptions (the very important
process of thinking up these assumptions for a real problem is called
modelling) about the density or CDF of a random
vector
![]() .
Define
.
Define
![]() to be some function
of X (usually some statistic of interest). How can we compute
the distribution or CDF or density of Y?
to be some function
of X (usually some statistic of interest). How can we compute
the distribution or CDF or density of Y?
Method 1: compute the CDF by integration and differentiate to find fY.
Example:
![]() and
and ![]() .
Then
.
Then

Example:
![]() ,
i.e.
,
i.e.

![\begin{displaymath}f_Y(y) = \left\{ \begin{array}{ll}
0 & y < 0
\\
\frac{d}{dy...
...\right] & y > 0
\\
\mbox{undefined} & y=0
\end{array}\right.
\end{displaymath}](img24.gif)


We will find indicator notation useful:


Notice:
I never evaluated FY before differentiating it. In fact
FY and FZ are integrals I can't do but I can differentiate then anyway.
You should remember the fundamental theorem of calculus:
Method 2: Change of variables.
Now assume g is one to one.
I will do the case where g is increasing
and I will be assuming that g is differentiable.
The density has the following interpretation (mathematically
what follows is just the expression of the fact that
the density is the derivative of the cdf):
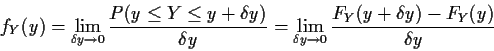
Remark: If g had been decreasing the
derivative ![]() would have been negative but in
the argument above the interval
would have been negative but in
the argument above the interval
![]() would have to have been written in the other order.
This would have meant that our formula had
would have to have been written in the other order.
This would have meant that our formula had
![]() .
In both cases this amounts to the formula
.
In both cases this amounts to the formula
Example:
![]() or (see Chapter 3 for definitions of a number of ``standard''
distributions)
or (see Chapter 3 for definitions of a number of ``standard''
distributions)

Let ![]() so that
so that
![]() .
Setting
.
Setting ![]() and solving
gives
and solving
gives ![]() so that
g-1(y) = ey. Then
so that
g-1(y) = ey. Then
![]() and
and
![]() .
Hence
.
Hence


