![]()
![]()
![]()
Two elementary definitions of expected values:
Defn: If ![]() has density
has density ![]() then
then

Defn: If ![]() has discrete density
has discrete density ![]() then
then
FACT: If ![]() for a smooth
for a smooth ![]()
 |
||
 |
||
In general, there are random variables which are neither absolutely
continuous nor discrete. Here's how probabilists define ![]() in general.
in general.
Defn: RV ![]() is simple if we can write
is simple if we can write

Defn: For a simple rv ![]() define
define
For positive random variables which are not simple we extend our definition by approximation:
Defn: If ![]() then
then
Defn: We call ![]() integrable if
integrable if
Facts: ![]() is a linear, monotone, positive operator:
is a linear, monotone, positive operator:
Major technical theorems:
Monotone Convergence: If
![]() and
and
![]() (which has to exist) then
(which has to exist) then
Dominated Convergence: If
![]() and
and ![]() rv
rv ![]() such that
such that ![]() (technical
details of this convergence later in the course) and
a random variable
(technical
details of this convergence later in the course) and
a random variable ![]() such that
such that ![]() with
with
![]() then
then
Fatou's Lemma: If ![]() then
then
Theorem: With this definition of ![]() if
if ![]() has density
has density
![]() (even in
(even in ![]() say) and
say) and ![]() then
then

Firts conclusion works, e.g., even if ![]() has a density but
has a density but ![]() doesn't.
doesn't.
Defn: The
![]() moment (about the origin) of a real
rv
moment (about the origin) of a real
rv ![]() is
is
![]() (provided it exists).
We generally use
(provided it exists).
We generally use
![]() for
for ![]() .
.
Defn: The
![]() central moment is
central moment is
Defn: For an ![]() valued random vector
valued random vector ![]()
Defn: The (
![]() ) variance covariance matrix of
) variance covariance matrix of ![]() is
is
Moments and probabilities of rare events are closely connected as will be seen in a number of important probability theorems.
Example: Markov's inequality
![$\displaystyle \le E\left[\frac{\vert X-\mu\vert^r}{t^r}1(\vert X-\mu\vert \ge t)\right]$](img58.gif) |
||
![$\displaystyle \le \frac{E[\vert X-\mu\vert^r]}{t^r}$](img59.gif) |
Special Case: Chebyshev's inequality

Example moments: If ![]() is standard normal then
is standard normal then
 |
||
 |
||
 |
||
 |
||
 |


If now
![]() , that is,
, that is,
![]() ,
then
,
then
![]() and
and
Similarly for
![]() we have
we have ![]() with
with
![]() and
and
Theorem: If
![]() are independent and each
are independent and each ![]() is
integrable then
is
integrable then
![]() is integrable and
is integrable and
Proof: Suppose each ![]() is simple:
is simple:

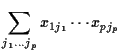 |
||
|
||
|
||
 |
||
 |
||
Let ![]() be
be ![]() rounded down to nearest multiple of
rounded down to nearest multiple of ![]() (to
maximum of
(to
maximum of ![]() ).
).
That is: if

Apply case just done:
For general case
write each ![]() as difference of positive and negative
parts:
as difference of positive and negative
parts:
![]()
![]()
![]()