Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| Language Reference |
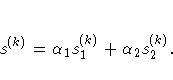
| Value of opt[4] | Update Method |
| 1 | Dual BFGS update of the Cholesky factor of the Hessian matrix. |
| This is the default. | |
| 2 | Dual DFP update of the Cholesky factor of the Hessian matrix |
In addition to the standard iteration history, the NLPDD routine prints the following information:
The following statements invoke the NLPDD subroutine to solve the constrained Betts optimization problem (see "Constrained Betts Function" ). The iteration history is shown in Figure 17.1.
proc iml;
start F_BETTS(x);
f = .01 * x[1] * x[1] + x[2] * x[2] - 100.;
return(f);
finish F_BETTS;
con = { 2. -50. . .,
50. 50. . .,
10. -1. 1. 10.};
x = {-1. -1.};
optn = {0 1};
call nlpdd(rc,xres,"F_BETTS",x,optn,con);
quit;
Double Dogleg Optimization
Dual Broyden - Fletcher - Goldfarb - Shanno Update (DBFGS)
Without Parameter Scaling
Gradient Computed by Finite Differences
Parameter Estimates 2
Lower Bounds 2
Upper Bounds 2
Linear Constraints 1
Optimization Start
Active Constraints 0 Objective Function -98.5376
Max Abs Gradient Element 2 Radius 1
Function Active Objective
Iter Restarts Calls Constraints Function
1 0 2 0 -99.54678
2 0 3 0 -99.59120
3 0 5 0 -99.90252
4 0 6 1 -99.96000
5 0 7 1 -99.96000
6 0 8 1 -99.96000
Objective Max Abs Slope of
Function Gradient Search
Iter Change Element Lambda Direction
1 1.0092 0.1346 6.012 -1.805
2 0.0444 0.1279 0 -0.0228
3 0.3113 0.0624 0 -0.209
4 0.0575 0.00432 0 -0.0975
5 4.66E-6 0.000079 0 -458E-8
6 1.559E-9 0 0 -16E-10
Optimization Results
Iterations 6 Function Calls 9
Gradient Calls 8 Active Constraints 1
Objective Function -99.96 Max Abs Gradient Element 0
Slope of Search Direction -1.56621E-9 Radius 1
GCONV convergence criterion satisfied.
Figure 17.1: Iteration History for the NLPDD Subroutine
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.