| |
The clustering of patient addresses is the primary step in increasing the efficiency and effectiveness of home support scheduling for VIHA. Our study has shown that the integration of multiple software platforms is not only possible but advantageous for the analysis of patient address clusters. Using the SANET toolbox extension as our foundation, we were able to integrate ArcMap, SANET, R, and Microsoft Excel software platforms, effectively extending the capability of the software for practical application. To optimize VIHA’s home support scheduling we successfully applied our model to assign cluster memberships to patient addresses which could then be visualized in ArcMap or used in an Excel spreadsheet for scheduling. Additionally, using the clusters created through this process we were able to determine within cluster travel distance and cluster to cluster travel distance, both which further influence home support worker scheduling.
In addition to proving the validity of this integrated software model, our methods also overcame the limitations of traditional Euclidean point cluster analysis. As highlighted in Fig 4, spatial network cluster analysis is able to analyse distance as experienced by a home support worker and thus is more applicable to home support scheduling. Our spatial network cluster analysis correctly identified when patient addresses, relatively near in Euclidean distance, were in fact relatively far in networked distance. Conversely, it correctly identified when patient addresses relatively far in Euclidean distance were close when measure along a network. These results were confirmed by comparison with Euclidean cluster analysis undertaken in S PLUS.
The strength of spatial network cluster analysis is its ability to account for the geometric and topological properties of networked space (Lu 2005) and thus better captures lived experiences. While empirical work concerning patient addresses within a healthcare context is lacking, studies examining crime incidents and traffic accidents have shown similar advantages. Yamada and Thill (2004) applied similar methods to the detection of traffic accident clusters, determining in the end that planar methods were unsuitable for activities constrained to a road network. These findings agree with those of Steenberghen et al. (2004) who located high traffic accident locations in Mechelen, Belgium. Again, networked application of cluster analysis was found to be superior to planar applications. Likewise, Lu (2005) found that the extension of planar cluster analysis techniques to networked space returned a high number of false positives and false negatives in regards to cluster identification of auto theft incidents in San Antonio, Texas.
Other studies have illustrated the limitations of spatial network cluster analysis. Researchers have found that significant difference in measured distance between spatial network cluster analysis and Euclidean cluster analysis was only found where points were less than 500m from each other (Okabe and Satoh 2009). However, within heavily networked areas, such as cities, this distance of significance varies greatly (Okabe and Satoh 2009). Additionally, for the purposes of our application with VIHA, the distances between patient addresses could vary greatly so spatial network cluster analysis remains the appropriate method for analysis.
The diversity of these examples illustrates the wide applicability of spatial network cluster analysis to a number of spatial problems. Spatial network cluster analysis is advantageous because the vast majority of human social and economic systems are constrained to a network. They are able to analyse the world in networked space which is the space in which humans live and make decisions (Okabe and Sugihara 2012).
Despite these advances, our study was not without its limitations. The primary limitation of our method stems from the SANET software’s inability to create clusters according to the criteria required by VIHA. The SANET Point Cluster Analysis tool is limited in that it can only identify clusters of patient addresses that exist naturally. It cannot delineate patient addresses along arbitrarily determined lines such as VIHA’s criteria that a cluster contain 30 patient addresses or that patient addresses within a cluster are no more than 10 minutes driving time from each other.
This limitation, in conjunction with our dependence on randomly generated points, also undermined our ability to prove the universal applicability of the model. While the model worked for some LHAs it did not work for all of them (Figure 7). The purpose of spatial network cluster analysis is to detect spatially agglomerated points existing along a network (Okabe and Sugihara 2012). Without actual patient data we were required to create randomly generated points on the road network. The use of random points along the network effectively negated SANET’s ability to detect clusters and ascribe cluster membership.
An additional flaw in our methods was the inability to automate the model as originally required by VIHA. The lack of integration between ArcMap and the SANET toolbox extension prevented the creation of models through the ArcGIS model builder and subsequently full automation of the model. Additionally, SANET tools could not be programmed using Python code language through the ArcGIS interface. Instead tasks were limited to the manual operation of SANET tools through the SANET toolbar.
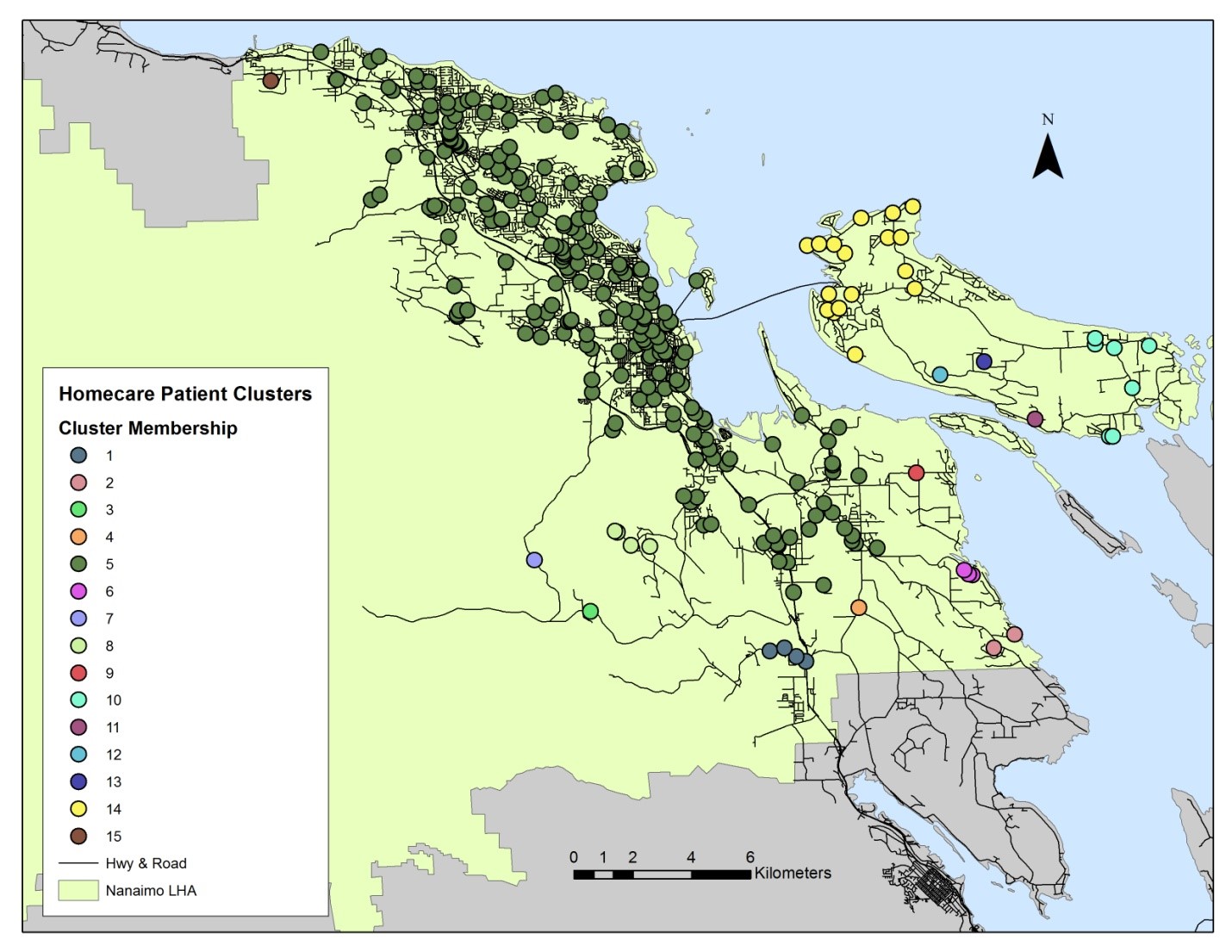
Figure 7. Poor clustering results arising from the use of randomly generated points in the Nanaimo LHA. (Click Image to Zoom)
While the technical components of our study still present challenges more theoretical issues also remain unaddressed. The aim of our project was to determine clusters of patient addresses based on travel time between patients. For the purposes of our study we used weighted distances to approximate travel times. Looking past the appropriateness of our weighting criteria, simply the inverse of standardized speed limits, there remains the issue of basing our analysis on a static and purely quantitative representation of the road network. Road conditions change from hour to hour and week to week leading to variation in travel times along the road network. This in turn may invalidate our clustering results. Furthermore, qualitative data regarding home support worker road preference was not incorporated into our model. Workers may prefer to take back streets to reach their patients as they find them less stressful. The omission of this data may also invalidate our clustering results.
The study design was also flawed as a result of the potentially conflicting criteria used by VIHA. VIHA stated that a cluster should have 30 patient addresses and that the patient addresses within a cluster should not be more than 10 minutes driving time from each other. However, in certain instances patients may be widely dispersed across a rural landscape well beyond a 10 minute driving time. Additionally, there may cases where in order to attain 30 patients within a cluster the driving time between patient addresses must be ignored. This issue is not intractable as it can be addressed by implementing a soft criteria approach.
TOP
|
|
