Identifying Radical Text Online
Primary Contributors:



Uncovering signs of extremism online has been one of the most significant policy issues faced by law enforcement agencies and security officials worldwide, and the current focus of government-funded research has been on the development of advanced information technologies to identify and counter the threat of violent extremism on the Internet. Here scholars have argued that successfully identifying online signs of extremism, especially on a large scale, is the first step in reacting to them. Yet in the last ten years alone, it is estimated that the number of individuals with access to the Internet has increased three-fold, from over 1 billion in 2005 to more than 3.6 billion as of 2017. With these new users, more information has been generated, leading to a constantly growing deluge of data. As the amount of data has increased, it has become harder and harder to sift through, and manual methods of research have become increasingly less efficient. These new conditions have necessitated guided data filtering methods, those that can side step the laborious manual methods that have been classically used to identify relevant information.
In response to these problems, we at the ICCRC have collected vast amounts of data via the Terrorism and Extremism Network Extractor (TENE), a custom-written computer program that automatically browses and captures all content from a pre-identified website. While the web-crawler has the capacity to extract any website or web-forum of our choosing, in total we have over 70 web-forums and over 30 websites featuring extremist content from radical Islamists and the radical right-wing. The ICCRC database, for example, includes web-forums such as Islamic Awakening, Gawaher, ShiaChat, and Stormfront. Websites include Muslim Brotherhood, Hizbollah, and Hamas sites, as well as Blood & Honour, Hammerskins, and World Church of Creator sites. With this data, we have conducted a number of studies using machine learning tools, with an emphasis on identifying radical users and websites. The following is a description of two key projects.
PROJECT 1: Identifying Radical Users in Online Discussion Forums
This project proposes a new search method that, through the analysis of authors’ sentiment, identifies the most radical users within online forums. Although this method is applicable to web-forums of any type, the method was evaluated on four Islamic forums containing approximately one million posts of its 26,000 unique users. Several characteristics of each user’s postings were examined, including their posting behavior and the content of their posts. The content was analyzed using Parts-of-Speech (POS) tagging, sentiment analysis, and a novel algorithm called “Sentiment-based Identification of Radical Authors” (SIRA), which accounts for a user’s percentile score for average sentiment score, volume of negative posts, severity of negative posts, and duration of negative posts (see Figure 1).
Combining sentiment analysis tools and the SIRA algorithm appears to be a useful way of identifying radical users – or, at the very least, users of interest to counter-extremism agencies – in the selected discussion forums. However, work on the SIRA algorithm remains in the early stages; it cannot detect or even predict the online sentiment that will (or may) result in an act of terror. While this particular identification exercise was not the intent of this study, we will assess this critical point, taking into account if a user is active during the time that the data is captured. Focusing on "currently active" authors may highlight how our strategy can be used to identify specific users who are of interest to counter-extremist agencies. In other words, our future research will incorporate a temporal analysis, examining how users’ radical scores change during their time on a forum. This strategy will involve splitting the entire dataset into clusters of months and calculating each user’s radical score for that month. From here, sharp changes in scores, especially ones that are most current, could be interpreted as possible changes in users’ motivation or level of “extremism” or negatively. This could help identify authors of interest and minimize the possible threat posed by violent Islamic extremists. Further, SIRA could also be used to identify very negative threads on the web-forums by aggregating the data to thread level, and not the author level. The incorporation of a social network perspective would also add an additional layer of analysis.
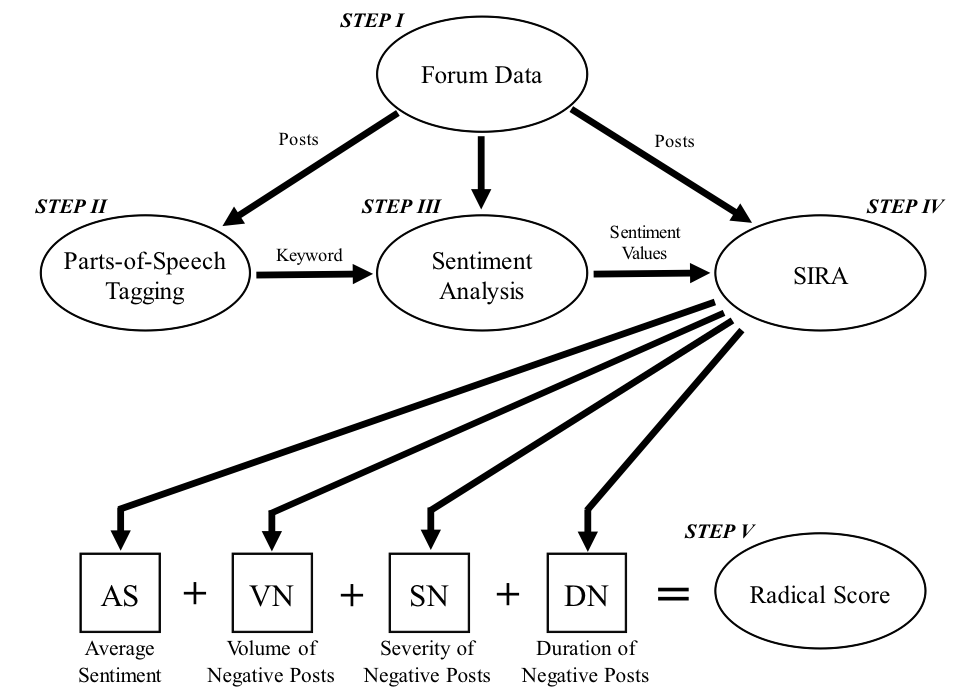
Figure 1. Process of Text Analysis and the Creation of the Radical Score
Relevant Publications:
Scrivens, R., Davies, G., & Frank, R. (2018). Measuring the Evolution of Radical Right-Wing Posting Behaviors Online. Deviant Behavior.
Scrivens, R., & Davies, G. (2018). Identifying Radical Content Online. Policy Options.
Scrivens, R., Davies, G., & Frank, R. (2017). Searching for Signs of Extremism on the Web: An Introduction to Sentiment-based Identification of Radical Authors. Behavioral Sciences of Terrorism and Political Aggression.
Scrivens, R., Davies, G., Frank, R., & Mei, J. (2015). Sentiment-based Identification of Radical Authors (SIRA). In Proceedings of the 2015 IEEE ICDM Workshop on Intelligence and Security Informatics (ISI).
PROJECT 2: Development of a Sentiment-Guided Web-Crawler
This project proposed an approach to building a self-guiding web-crawler to collect data specifically from extremist websites. The guidance component of the web-crawler was achieved through the use of sentiment-based classification rules, which allowed the crawler to make decisions about the content of the webpage it downloaded. First content from 2,500 webpages was collected for each of the four different sentiment-based classes: pro-extremist websites, anti-extremist websites, news sites discussing extremism, and finally sites with no discussion of extremism. Parts-of-Speech (POS) tagging was then used to find the most frequent keywords in these pages. Utilizing sentiment software in conjunction with classification software, a decision tree that could effectively discern which class a particular page would fall into was generated (see Figure 2). The resulting tree showed an 80% success rate at differentiating between the four classes and a 92% success rate at classifying extremist pages specifically.
Perhaps the most promising application would involve a near fully automated version of the abovementioned approach. Many of the manual steps done in this study could be automated, reducing the amount of human error. However, Dr. Frank and Ryan Scrivens are currently working with Professor Maura Conway from Dublin City University to analyze, from a qualitative perspective, how effective the sentiment-guided web-crawler is at differentiating violent radical Islamist websites from violent radical right-wing sites.
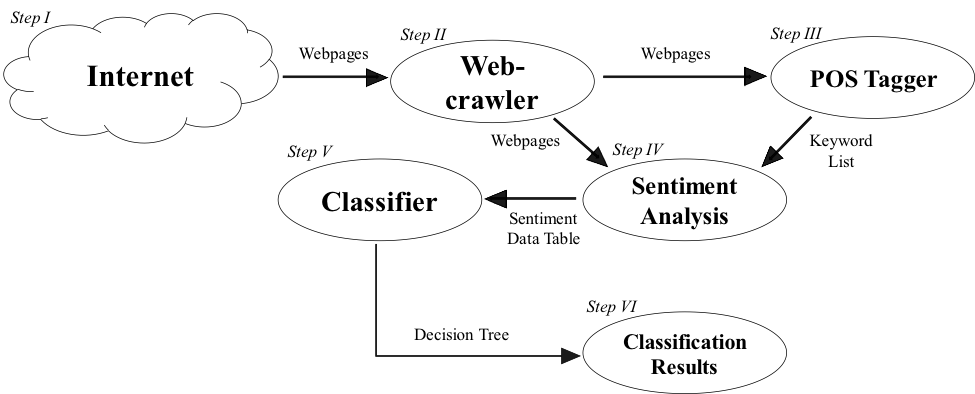
Figure 2. Data Collection and Tree Generation Process
Relevant Publications:
Scrivens, R., & Frank, R. (2016). Sentiment-based Classification of Radical Text on the Web. In Proceedings of the 2016 European Intelligence and Security Informatics Conference (EISIC).
Mei, J., & Frank, R. (2015). Sentiment Crawling: Extremist Content Collection through a Sentiment Analysis Guided Web-Crawler. In Proceedings of the International Symposium on Foundations of Open Source Intelligence and Security Informatics (FOSINT).
Future Projects:
Conway, M., Scrivens, R., & Frank, R.: “Classifying Extremist Text on the Web: A Quality Check of a Sentiment-Guided Web-Crawler.”