The
human ability to vocalize sound, as well as the
soundmaking abilities of other species, is amazingly complex
and endlessly fascinating. Speech, song, and non-verbal
behaviour is central to all aspects of individual and cultural
development, and therefore plays an extremely important role
in acoustic communication.
In many cases, when we turn to the study of acoustics and
psychoacoustics, we can find strong evidence that vocal
soundmaking establishes many of the norms for understanding
sound in general, particularly the way in which spectral and
temporal patterns are produced and processed by the auditory
system.
We can only summarize here the most basic information in this
extensive field, as subdivided into these categories.
A) The acoustics of speech
production: vowels and consonants
B) Linguistic descriptions of vowels and
consonants
C) Reading a sonogram
D) Voice and soundmaking on a personal and
interpersonal level; paralanguage
E) Soundmaking in cultural contexts
F) Cross-cultural forms of vocal
soundmaking
Q) Review Quiz
home
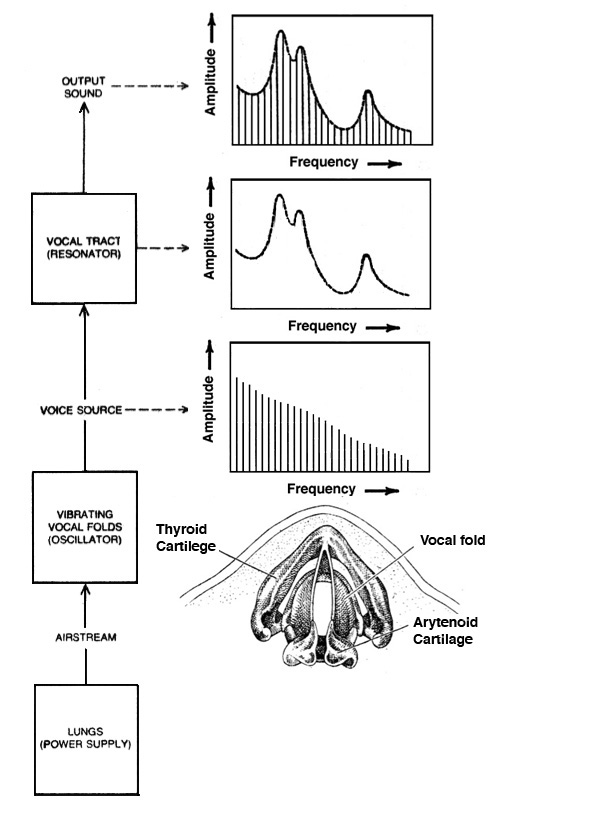
A. The acoustics of speech production.
The simplest acoustic model of the voice, as shown below, is
where an airstream originating in the lungs, supported by
the diaphragm, is the power source that has the option of
being periodically modulated by the vocal folds
(also known as the vocal cords – note the spelling), which
is then filtered through the vocal tract acting as a
variable resonator. This model is often called the source-filter
model and can be simulated with a periodic impulse
train, whose spectrum is the set of harmonics with
decreasing amplitude, that passes through the vocal tract
which is modelled by a filter to create a set of resonant
frequencies called formants.

Vocal folds
closing and opening (source: Denes & Pinson)
The vocal tract includes the larynx, the pharynx
above it, the mouth and optionally the very large nasal
cavity, all of which act as a variable resonator.
The main determinant of the frequency response of this
resonator is the tongue position, and this is how
different vowels are created. In the following sound
example, we first hear a single glottal pulse, followed by
that single pulse put through three different filters, and
with such a minimal model, it may be surprising that you can
already hear different vowels. This is because the spectral
envelope with its characteristic peaks is already activating
a spatial pattern of excitation along the basilar membrane,
as discussed in the second Vibration
module. Then we hear a periodic set of those pulses
(rather harsh but still a harmonic spectrum), followed by
putting them through the three filters again to produce the
vowels "ahh", "eeh", and "ooo".
Glottal
pulse, then heard through 3 filters; glottal pulse
train, then through the same filters
(Source: Cook 5) |
Click
to enlarge |
An
alternative demonstration is a simple transition from a
closed mouth hum (which emphasizes the harmonics produced by
the vocal folds) to an open mouth, sustained vowel ”aah” in
this video version of
the example. Note how the waveform shown in the oscilloscope
becomes more complex after the transition, the spectrum gets
richer with the formant regions, and the sound gets louder.
A key characteristic of this system is that
the vibration of the vocal folds, producing a pitched
sound in normal speech, is largely independent of
the vocal tract resonances. In other words, higher or lower
pitches will sound like the same vowel when the tongue stays
fixed and therefore the resonances are also fixed. When you
sound the vowel “aah” at different pitches, for instance,
you will notice that your vocal tract (and tongue) stays in
one configuration. However, with the singing voice, it is
difficult to produce certain vowels on a high pitch.
Since formant frequencies are fixed for a given vowel,
they cannot be transposed in pitch and remain recognizable,
beyond about a plus or minus 10% shift in pitch (which is
less than a whole tone in music). On the other hand, the
speaking pitch range can easily vary over an octave or more.
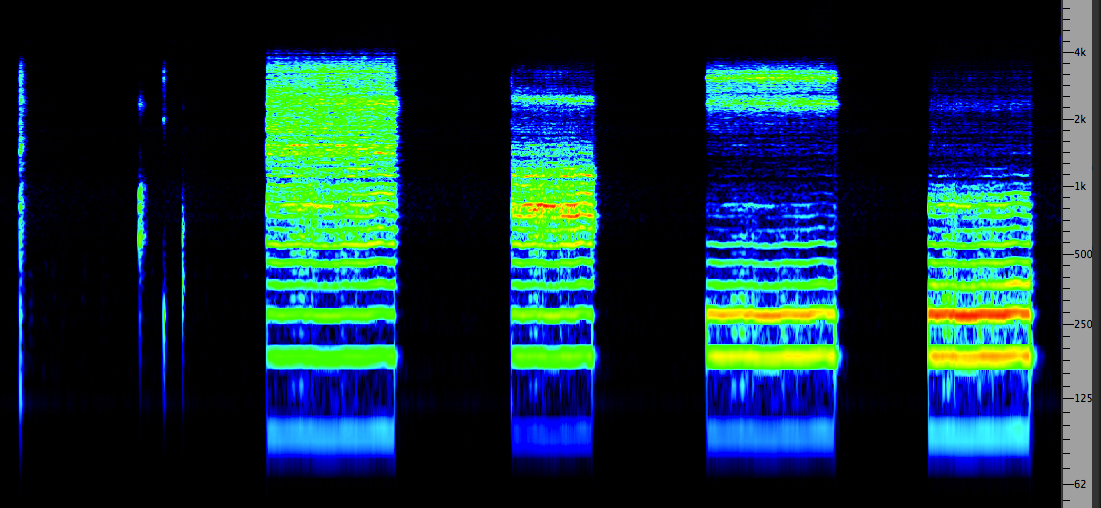
The following example transposes speech by a 3:1 ratio, at
which point the sound of the voice is often referred to as
the “chipmunk effect” (because of a popular music
phenomenon in the late 1950s known as Alvin and the
Chipmunks which used this effect with humorous intent).
However, an acceptable degree of realism is restored by
using a phase vocoder technique to scale the
frequency and time domains independently. After the original
version in this example, it is transposed up by a factor of
three. Then, in the third part of the example, the pitch is
also raised by the 3:1 ratio, but the original formant shape
is kept intact, and comprehension is improved.
Original
speech example, then transposed by 3:1 without and
with formant correction
Source: Pierce 48 & 53 |
Spectrogram
of second and third parts; click to enlarge
|
Formant frequencies. What
determines the frequencies of the formants? First of all,
keep in mind that a formant is a narrow, resonant band of
frequencies, so when we refer to the formant frequency,
we are pointing to the centre frequency of that
band.
In order to understand how formants are placed, we can
recall the basic modes of vibration in a tube closed
at one end, and open at the other, as documented in the
first Vibration module. If
we imagine the vocal tract as such a tube (which would make
us look very odd!), then the resonant frequencies would be
the set of odd harmonics, because the fundamental
mode of vibration corresponds to 1/4 wavelength, and the
other modes to its odd multiples, as shown in the diagram
below.
There are theoretically an infinite number of those resonant
modes, but we will show just the first four, as the strength
of the higher ones falls off quickly. However, the actual
shape of the vocal tract is irregular, hence the broadening
of the resonant energy into the formant shape, but to start
from first principles, let’s return to the tube closed at
one end (the vocal folds) and open at the other (the mouth).
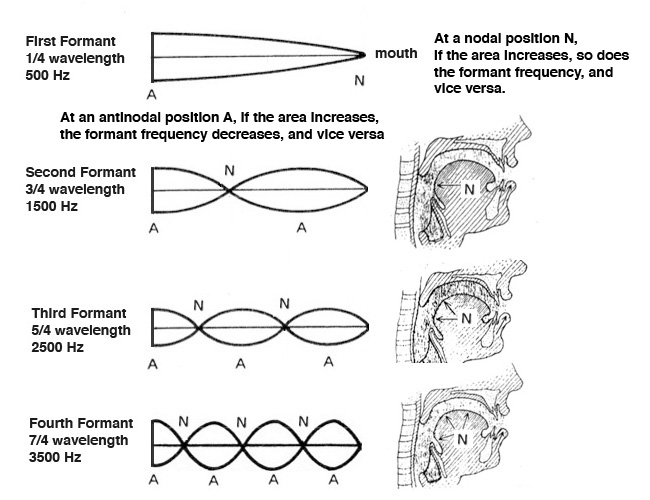
If the average male vocal tract is about 7” (17.5 cm) long,
and the fundamental mode is 1/4 wavelength, then a full
wavelength is about 28” (70 cm) which corresponds to
approximately 500 Hz. The odd harmonics, then are
1500, 2500 and 3500 as noted in the diagram. The female
vocal tract, being shorter, is likely to have formant
frequencies 10-20% higher than that.
The diagram also notes the positions of minimum pressure,
the nodes (marked N), and the maximum pressure
positions, the antinodes (marked A). The mouth is a
nodal position for the first formant, and the diagrams for
the other formants show the approximate position of the
nodes inside the vocal tract. The rule is that as the
area of the vocal tract increases at a nodal position, the
formant frequency rises as well. Vice versa, if it
decreases, then the formant frequency falls. An inverse
relation applies for the antinodes at a position where the
area changes.
The following table lists the first three
formant
(i.e. centre) frequencies F1, F2 and F3, (the most essential
ones to identify a vowel) for the adult male and female, as
well as for children. A simple example of the area of the
vocal tract changing is with the open mouth vowel “aah”
where the first male formant has risen to 570 Hz, and the
closed mouth “eeh” where it has fallen to 270 Hz.
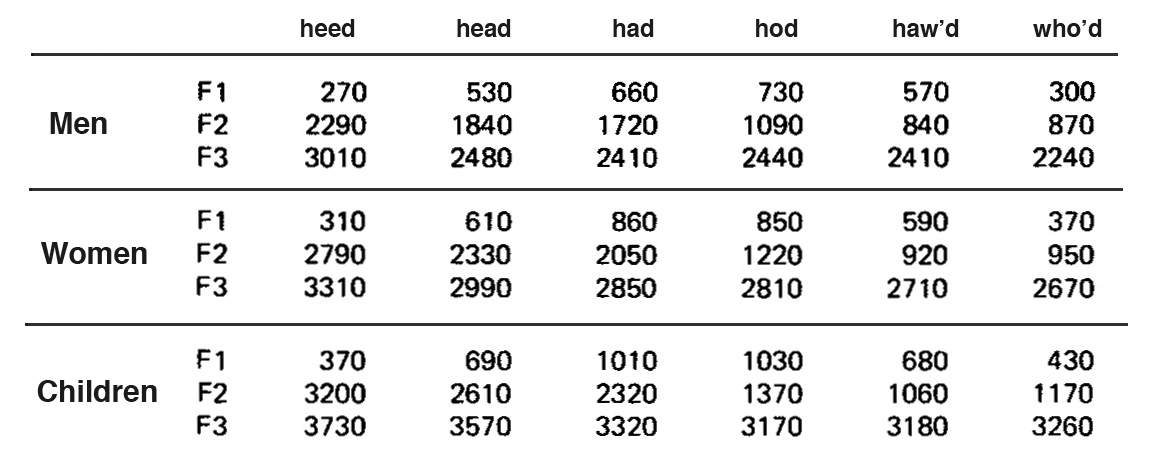
Table of formant frequencies for
men, women and children
Note that for these typical measurements, the vowel has been
placed in a “consonantal environment”, namely a soft attack
“h” and a hard consonant ending “d” in order to standardize
the formant positions. In a continuous speech stream, the
tongue may need to move to a new position right after the
vowel (for instance, to a closed mouth “n”) which will cause
the vowel formants to shift. Therefore, this table
represents a static situation.
Perry Cook has programmed a vocal
simulator based on the
source-filter model, and in this next example he has
modelled several tongue positions and their respective
formants. However, only the first three are recognizably
correct and plausible, and the last two are “unreasonable”
because they can’t be physically produced by any tongue
position. You’ll probably find them quite funny, as you try
to imagine someone contorting their mouth into such a weird
shape!
Five
vocal tract simulations, the last two
"unreasonable"
Source: Cook 39
|
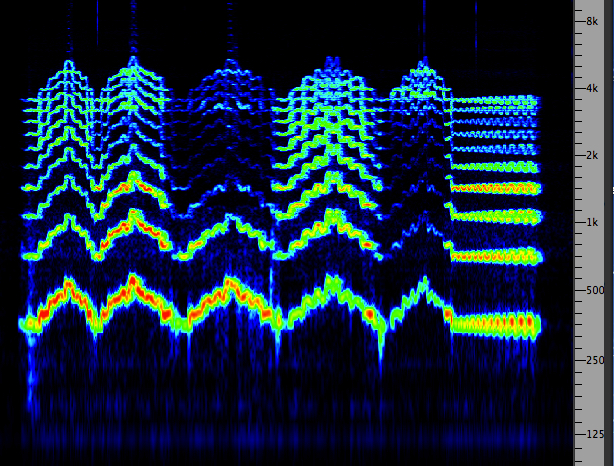
|
The Singing Formant. The Swedish
speech acoustician Johan Sundberg studied the singing voice
with a great deal of research into the scientific principles
involved, during the 1970s and until his retirement in 2001,
culminating in his book The Science of the Singing Voice.
Here we will only outline one major finding, with the
recommendation of reading his work further and viewing some
of the lectures that are available online.
In particular Sundberg is associated with identifying the singing
formant. This refers to a vocal technique that is
developed mainly in opera singers to project their voice
over an orchestra. The difference in that type of voice is
the presence of an added (or perhaps “amplified”) resonance
region in the 2-3 kHz range. Given our sensitivity
to those frequencies, this added spectral component allows
the unamplified vocal sound to be heard above a full
orchestra. Here is an example comparing this type of trained
voice to a more conventional one, using vocal synthesis.
Singer
with and without the singing formant; synthesized voice
Source: Cook 42 |
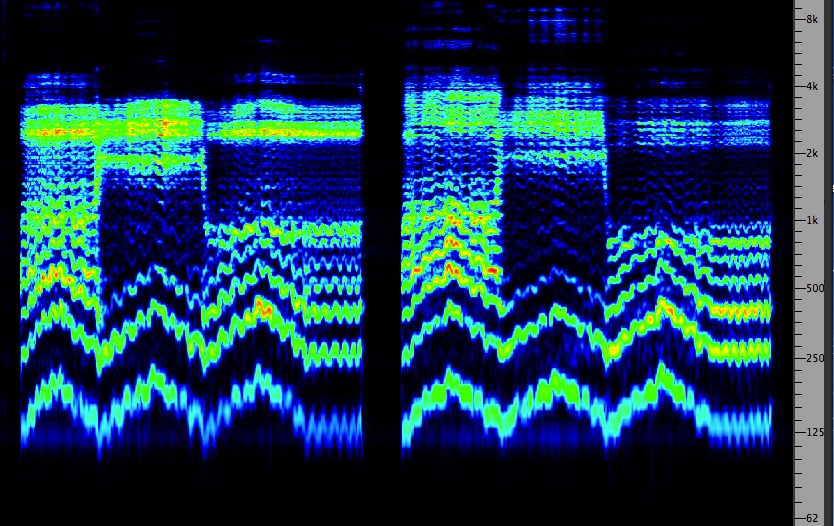
Click
to enlarge
|
The
historic reason for this development in the Western operatic
tradition is an interesting confluence of acoustic and
cultural influences. In the second half of the 19th century,
opera houses with performances for a larger paying audience
had become the norm, and at the same time, many of the
orchestral instruments had been re-designed to be louder in
order for their sound to fill the hall. Also, in many cases,
the actual number of instruments in the orchestra had
increased, sometimes to over 100.
Opera singers prior to that period generally had lighter and
more agile voices, culminating in the “bel canto” repertoire
of the first half of the 19th century. However, it was very
difficult to make this style of singing louder without
losing pitch accuracy and the comprehension of the text. The
“solution” was the type of vocal enhancement described by
the singing formant, and the result was a new type of singer
that is now associated with “grand opera”.
The irony in the 20th century is that amplification could
have been used with the earlier types of voices, but the
prejudice against using that solution remains today (as
being too much associated with musical theatre). However,
historically informed performances of works prior to the
19th century have become more widely available, and singers
who specialize in that repertoire do not necessarily have to
resort to the singing formant approach.
Diphthongs. The above examples are
called the pure vowels because they have a fixed
tongue position and fixed set of formant frequencies.
However, the tongue and mouth can move during a vowel and
create sliding formants. These are called diphthongs,
which is hard to say and even hard to spell. We will list
the possible ones in English in the next section, but for
now let’s look at an extreme example, namely going from an
“aah” to an “eee”.
This diphthong seems extreme because we go from an open
mouth to a nearly closed one, but more dramatic is the
raising of the tongue towards the top of the mouth which
reduces the area at the antinode (A) between the two nodal
positions shown above. This results in a huge rise of the
second formant from 840 Hz to 2290 Hz (see the table under
the male “haw’d” and “heed” and check the position of the
antinode for the second formant in the diagram above it).
Also, try doing this yourself.
You can watch the transition in the video example, and
notice the huge gap in the middle of the spectrum with the
“eee”. The partial closing of the mouth also makes the sound
weaker, but in general we think of “eee” as a bright
vowel because of the two high formants (2nd and 3rd).
Finally you can compare the two waveforms of the
vowels in a steady state, as below. Because of the shape of
the glottal pulse, vowel waveforms are not symmetrical
above and below the zero axis, as in a sine wave or other
free vibration. If a simulation lacked that character, it
would not sound realistic.
Video
example of an
extended diphthong
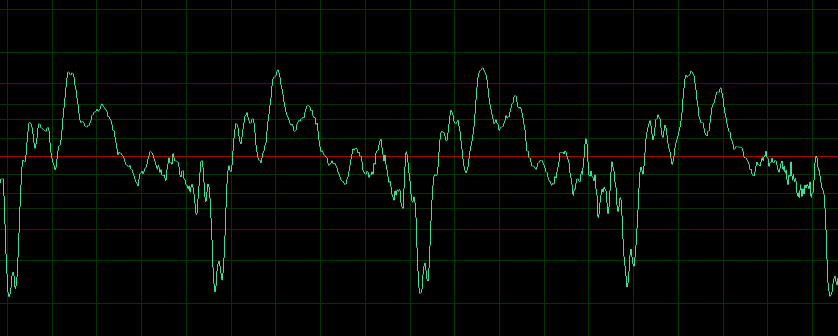
Waveform of the vowel "aah"
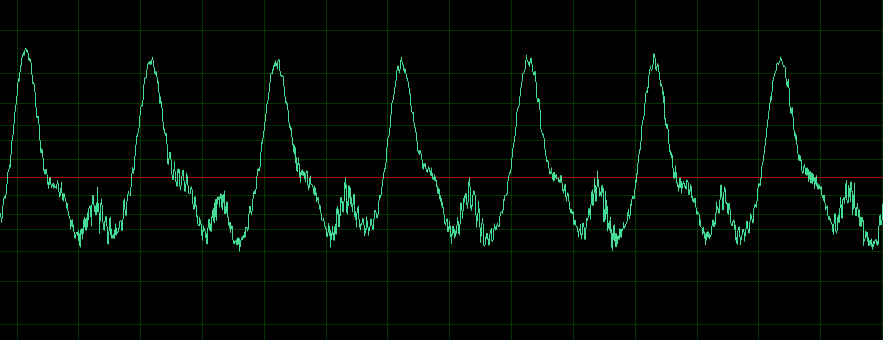
Waveform of the vowel "eee"
|

Diphthong
spectrum
aah to eee
|
Consonants. Thus far we have been
exploring the source-filter model for vocal production, and
it can also be used for the production of consonants.
However, what it will produce is a spectral analysis
of the noise bands associated with the consonants in terms
of the airstream moving through the vocal apparatus. What it
omits is their temporal envelope which is arguably
more important for their identification.
Consonants, like speech in general, can be voiced –
that is, with the vibration of the vocal folds and hence a
pitch – or unvoiced, without those vibrations and
pitch (also called voiceless). Whispering is an
example of unvoiced speech, and yet we can still understand
it. We even think we can hear pitch rises and falls simply
from the cues provided by the vocal tract resonances.
In Hildegard Westerkamp’s 1975 work Whisper Study,
she whispers a sentence from Kirpal Singh quite close to the
mike. Despite the absence of any voicing of the vowels, the
text remains clear and the consonants are prominent. Compare
the spectrum for the whispered text with her speaking it
normally. Besides the consonants, the upper formants of the
vowels still retain their character.
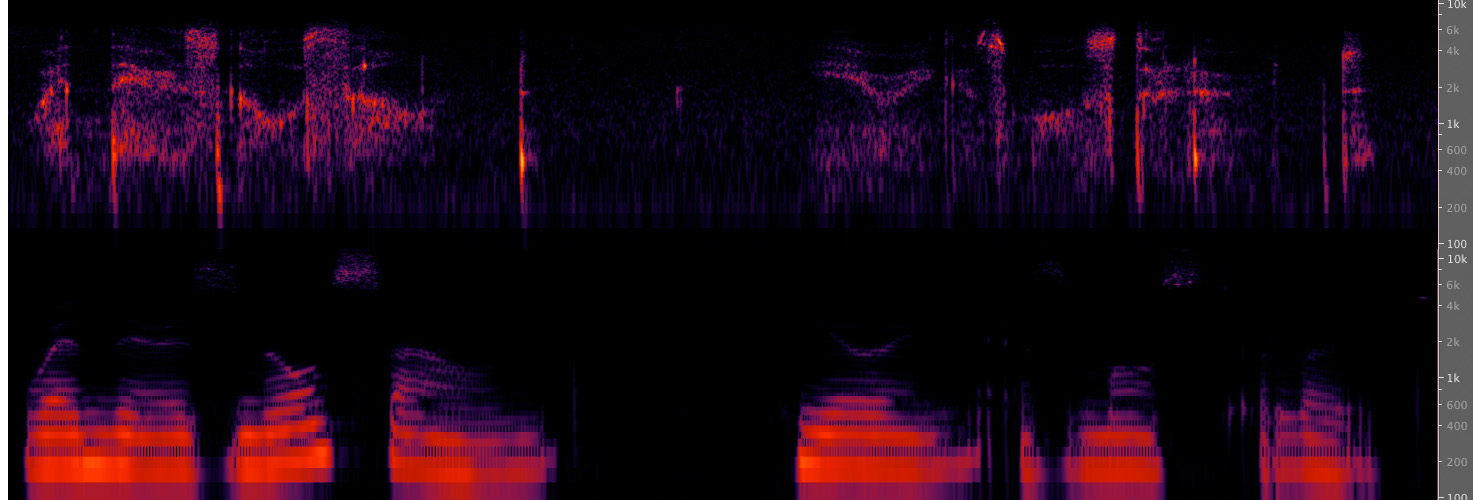
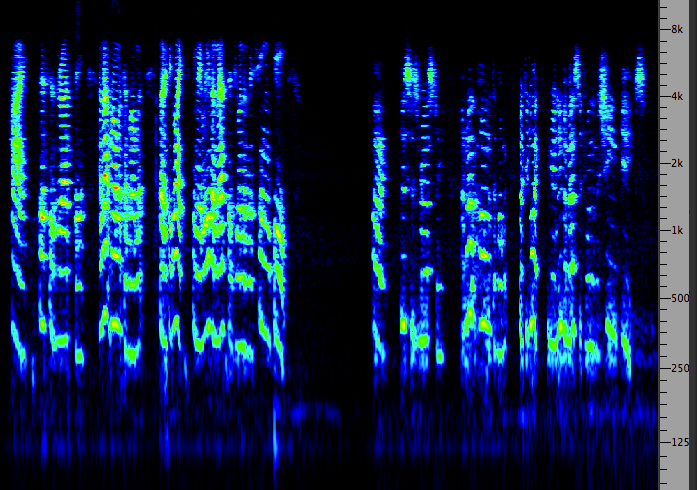
(top) Spectrum of whispered text
(bottom) Spectrum of spoken text (click to enlarge)
|
Westerkamp
whispered text
|
Consonants
can be voiced or unvoiced, as we will document in the next
section, because they depend on the place and manner of their
articulation, as classified by linguists. Here we will simply
present the source-filter model using noise as a source (the
first sound) and four filter settings that produce differing
bandwidths and distributions of the noise, simulating the
unvoiced consonants "fff", "sss", "shh" and "xxx".
Noise
band put through 4 filter settings to simulate
consonants
Source:
Cook 30
|

Click
to enlarge
|
Index
B. Linguistic descriptions of vowels and
consonants. The basic units of a spoken language are
the phonemes
which are specific to an individual language, and
generally classified as vowels and consonants. English,
for instance, has about 44 phonemes. Linguists categorize
vowels according to the tongue position, and
sometimes display a graph of the first formant mapped
against the second. This implies that only two
formants are needed to identify a vowel, which is
fine for linguistic purposes, but in terms of a
re-synthesis of the voice, the third formant (at
least) should be included for realism, as listed in the
above table.
The small oval diagram at the left below shows the
position of the tongue within the mouth (which is placed
at the far left) in its extremes of sliding towards the
back of the mouth along the hard palate at the top, then
to the soft palate at the back, as shown in the upper
curve of the diagram. The lower curve follows the tongue
sliding back along the bottom of the mouth. You can try
doing this consciously, but it feels tricky to do smoothly
as it’s not a normal type of tongue movement in the mouth.
Instead of the oval mapping of the mouth, linguists prefer
to show the vowels in the vowel quadrilateral as
shown at the right. The extreme positions that are
numbered are called the cardinal vowels (which
were also shown in the oval diagram). These represent
theoretical tongue positions that are not necessarily used
in any language, but a linguist can be trained to produce
them.
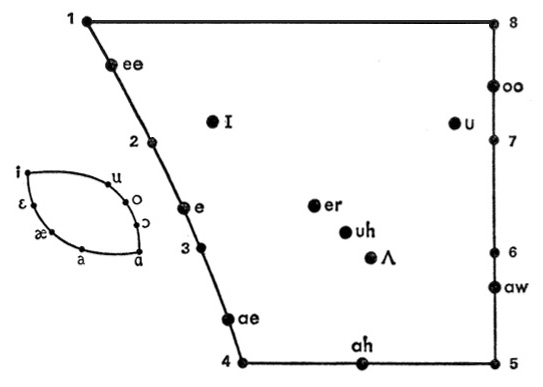
|
Vowel quadrilateral (left) and linguistic
representation of vowels and diphthongs (right)
Source: Denes & Pinson
|
The solid circles mark the tongue position for the pure
vowels we have been referencing in the first
section, since they involve a fixed tongue position in the
mouth. Again, you will see the “ee” vowel towards the
front of the mouth on the upper left side and the “aah”
vowel towards the back and bottom of the mouth on the
lower side of the diagram. The bright vowels are
usually at the front of the mouth, and the dark
ones towards the back.
Notice that the “hesitation” vowels (“er” and “uh”)
have the tongue placed near the centre of the mouth –
ready to move once you decide what you want to say! The
formants for those vowels will likely be the closest to
the odd harmonic spacing we saw in the modes of vibration
model above.
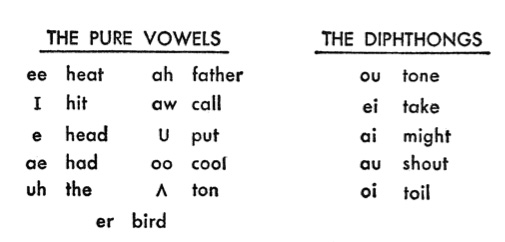
Linguists use phonetic spellings of the vowels,
and to help us understand them, usually provide a common
word to help us out (e.g. the I for the short
vowel “i” as in “hit”), as shown in the table at the
right.
Likewise we can see the five diphthongs that are
used in English in the table. If you practice each one
slowly you can feel how your mouth and tongue move to
create them. For instance, “ou” and “au” as in “tone” and
“shout”, involve a rounding of the mouth. However the long
“a”, labelled as “ei” as in “take”, and the long “i”,
labelled as “ai” as in “might”, are usually performed so
quickly that you might not think of them as diphthongs,
but try them slowly. Similarly with the "oi" as in "toil".
Try saying the word I (referring to yourself) very slowly
and you can feel yourself doing something similar to the
diphthong shown in the previous video (“aah” going to
“eee”). In practice, you might do this when you are
hesitating on the word I, when you don’t know which verb
you are going to use next, but in colloquial speech this
gets done very fast, and in fact the mouth just moves
towards the “eee” part of the sound without spending any
time there. So the brain's recognition pattern mechanism
just reacts to this suggested movement of the mouth
without you actually needing to hold the “eee” portion.
Different accents in spoken English around the world will
likely involve slightly different tongue positions from
those indicated on the vowel quadrilateral, and of
course native speakers have practiced the appropriate
musculature movement since childhood. Similarly, some
dialects introduce diphthongs into what would
normally be pure vowels, as in the famous “Southern
drawl”.
Learning a new language as a adult is notoriously
difficult, because of the learned musculature habits that
get in the way, among other issues. However, here’s an
example for how this can be re-learned. The French vowel
as in rue (a street, not the English word to
regret) is articulated at the front of the mouth, whereas
in English its equivalent is at the back. So if you don’t
want to sound like a dumb foreigner in France, try this
exercise. Use your learned mouth position for the vowel
“eee” and then round your lips, and this will get you in
the right ballpark – or perhaps the right street!
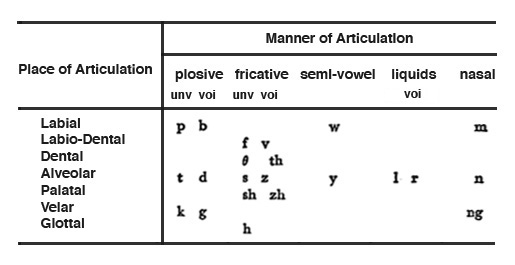
The consonants are classified
by linguists by their place and manner of articulation,
as shown in this table. The “place” in question is the
position of the tongue, going backwards from the
lips “labial”, to the teeth “dental” (and an intermediate
position in between), then the gums “alveolar”, the top of
the mouth “palate”, the soft palate at the back “velar”,
and at the very back of the mouth “glottal”. As mentioned
earlier, consonants can be voiced or unvoiced (as
marked by “voi” and “unv” respectively in this table).
 Consonants organized
according to their place and manner of articulation
Consonants organized
according to their place and manner of articulation
The manner
of articulation is key to the temporal pattern
of the consonant, and hence its recognition. The plosives
are created by blocking the air flow momentarily at the
mouth, and then releasing it, a kind of “explosion”. This is
well known to recordists for the pros and cons involved. The
down side is that if the explosion of air goes straight into
the microphone it will create a low frequency “pop” which
can be very distracting (but can be filtered out, as shown here). A windscreen can help,
but you can also place the mic about 30° to 40° degrees off
centre. Try placing your hand in front of your mouth and
vocalizing a “pah” sound; then move your hand to the side
until you no longer feel the air being expelled.
The useful side of the plosive for a sound editor, is the
fact that there is a short pause before the
consonant – and hence a perfect place to make an edit if it
is needed. The brief attack of the plosive may even
momentarily mask a slight change in ambience that might
otherwise be noticed.
Note that the plosives come in pairs of unvoiced (p,
t, k) and voiced (b, d, g). This voicing is brief,
but if you feel your throat around the Adam’s apple, you can
sense the short vibration involved along with the airstream,
even near the back of the mouth (the velar g).
The pattern recognition mechanism for a plosive can be
triggered merely by inserting silence into a set of
phonemes. Keep this in mind if someone carelessly suggests
that information is “in” a sound or a signal. Just as you
are more likely to notice a continuous sound only after it’s
stopped (since you have been habituated to it previously),
it is patterns of sound and silence that provide
information to the listener. In this simple example, on the
left, silence is inserted into the word “say”, first at 10
ms, then increasing to 20, 40, 60, 80, 100, 120 and 140 ms.
What new “word” do you hear?
Increasing
silence introduced into the word "say" Source:
Cook 44
|
Increasing
silence introduced into the phrase "gray ship"
Source: Cook 47
|
To add a
bit of further complexity to the example, many people hear
the common word “stay” which includes the alveolar plosive
“t”. However, for animal fanciers, the less common word
“spay” (i.e. to neuter a female animal) may also be heard.
In the right-hand example, there is a rather famous example
of perceptual re-organization where silences are edited into
the phrase “gray ship” where many variants of the words can
be detected.
Like many similar consonants, a key
difference that enables us to distinguish them is the shape
of the lips and mouth during their articulation. Most people
do not realize the extent to which they rely on lipreading
while listening to someone speak, although if they are
experiencing hearing impairment, they will start depending
on that skill to a much greater extent.
The plosive “b” involves closing the lips, whereas “d”
involves tongue movement around the gums, followed by the
same act of opening the mouth to expel the air. The “g”
plosive involves the tongue at the back of the mouth against
the soft palate. In a famous experiment called the McGurk
effect, you are asked to listen to some repeated
plosives without seeing the speaker, and then compare what
you’ve heard to seeing the speaker at the same time. Does
the sound you hear change? Try it with this video, which has no visuals at
first, followed by a close-up of the speaker.
Most everyone hears a “ba ba” in the audio only track, and
“da da” in the audio-visual version. This is because the
speaker’s lips and mouth are articulating a “d” plosive
while the synchronized soundtrack is a “b” plosive. It is a
good demonstration of how the visual and auditory faculties
interact – you’ll hear it once you see it.
The fricatives, as the name
suggests (as in friction), involve constricting the air
flow with the tongue position as indicated in the
table. Unlike the plosives, knowing which version of the
fricative to use, voiced or unvoiced, is a tricky issue for
foreigners learning English, as you cannot tell from the
spelling of the word in all cases. Possibly the worst is the
“th” fricative in English, first because it requires you to
put your tongue between your teeth – something that would
likely be regarded as rude in other cultures!
Notice the phonetic symbol θ for the unvoiced “th”
to distinguish it from the voiced version “th”. An
unvoiced example is “thin”, with the voiced version as in
“this”. Try saying “this thin” normally and then with the
phonemes reversed! Not easy, but how is one supposed to
learn which is used? Maybe you’ll understand why it
sometimes comes out as “dis” in a foreign accent.
The alveolar and palatal fricatives (ss, sh, ch and their
voiced versions, z and zh) are known as sibilants,
which are characterized by their strong energy in the high
frequency range, namely 5 - 10 kHz. Their presence is
collectively known as sibilance.
When their strength is augmented by close miking, as in
radio, they can be subjected to attenuation, called de-essing.
Here is a video
demonstration of the four pairs of unvoiced and
voiced fricatives where you can easily see the added
periodicity of the voiced version in the oscilloscope and
the dramatic spectral addition of the lower harmonics in the
spectrogram. These are good examples of pitch plus noise
in a sound. You can probably do the same switching on and
off of the voicing much more rapidly than in the example -
try it!
The glottal fricative “h” is only unvoiced and
produces a soft, airy attack for the next vowel (and can be
silent in some words, such as “hour”), and as such is used
as a neutral consonant before a vowel in the formant
frequency table above. In some languages, it is given more
of a guttural articulation, as in the Dutch “g”.
The semi-vowels (y and w) are
regarded as consonants because they are always linked to the
following vowel with a soft attack. They are both voiced,
with the “y” formed by putting the tongue towards the front,
similar to “ee”, and the “w” is created by rounding the lips
similar to an “oo”.
The two “liquid” consonants, l ("el") and r,
are voiced and usually described as having air flow around
the tongue (hence the fluid name), positioned near the gums
for the “l” and farther back for the “r” which is also
called a rhotic. In some languages and dialects it
is “rolled” which means amplitude
modulated.
The nasal consonants are also voiced, but because
the air is blocked from coming out of the mouth, they are
resonated in the very large nasal cavity (the
largest in the skull) connected to the vocal tract behind
the soft palate. Their strength can be subtle or strongly
pronounced (try emphasizing them, the m, n and ng and feel
the vibration in your head). Since there is no mechanism in
the voice for inharmonic modes of vibration (the
vocal folds always produce harmonics), we often resort to
the nasal consonant “ng” when we want to imitate a metallic
sound such as a bell ringing.
To conclude, the consonants act similarly to the
attack transients in a musical instrument or other
percussive sound. They arrive first at the auditory system,
are spectrally complex in terms of noise bands, and we are
very sensitive to their temporal shape. If they are missing,
masked or otherwise muted through hearing loss, speech
comprehension will quickly decrease.
Admittedly we can sometimes “fill in the blanks”, such as
when the high frequency sibilants are not transmitted over a
phone line, because of the redundancy in speech and the
familiarity of most words. However, many words differ only
in the consonants being used, or become indistinct because
of slurring words together. However, speech recognition also
reminds us that both spectral and temporal information
are being simultaneously collected in the auditory system,
and taken together can efficiently produce a great deal of
information.
Index
C. Reading a sonogram. We will now
return to the representation of speech in the sonogram
(or spectrograph), as introduced in the second Vibration module. Since
the 1940s, this visualization of speech has shown the
intricate acoustic structure of speech in a 3-dimensional
representation (frequency and time on the y and x axes,
respectively, with darkness of the lines showing
amplitude). Today there are many more colourful versions
of the same type of representation. The linear frequency
scale in this case is useful to examine the important role
of high frequencies.
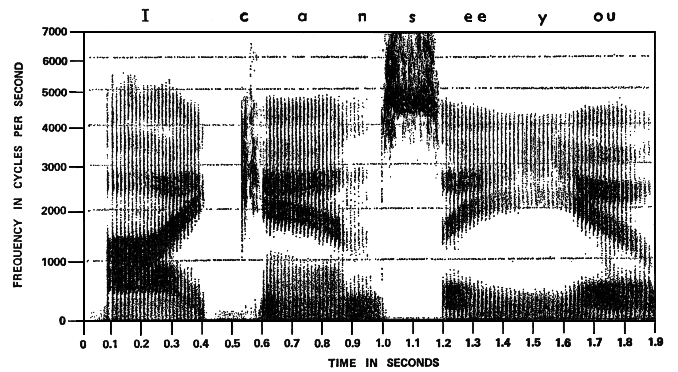
Speech sonogram
(source: Denes & Pinson)
In this
example, we are now in a position to discuss some features
of (slow, in this example) connected speech that are missing
from the categorizations used above. We will follow the
various phonemes being represented according to the text at
the top:
- the first word “I” is a diphthong,
and here we can see the characteristic rise in the second
formant towards the “ee”, without it being sustained at
the end
- the
consonant “c” (the plosive “k”) is clearly unvoiced
(no low frequencies) and resides in the 2-5 kHz range,
which distinguishes itself from an “ss” but not
necessarily a “t”
- the
vowel “ah” that follows is a pure vowel, but
notice that its formants glide slowly towards the closing
nasal “n” which required a closed mouth, hence the reason
for the formant shift; however, this does not make
it into a diphthong; the vowel recognition depends only on
the initial formant frequency placement
- the sibilant
“ss” is clearly very high frequency and unvoiced, also
longer, so the only ambiguity would be “ss” or “sh” but in
this case the frequency band is higher, so it’s an “ss”
-
again, another pure vowel “ee” gliding towards a semi-vowel
“y” because the tongue is moving towards the front; the
weak semi-vowel “y” then is just the soft start of the
final vowel which probably in the original ended with the
lips closed, hence the final drop in formants.
As you
can see, speech recognition by a machine has always been a
kind of elusive “holy grail”, because there are so many
patterns to recognize. It is also very difficult to do
without reference to syntactical knowledge, and sensitivity
to the variations in individual voices which usually
requires the user to “train” any algorithm, not to mention
how large a vocabulary is needed. Recently of course,
several successful apps have become available on our
smartphones, which represents a great deal of progress in
artificial intelligence.
Filtered speech. Although this
example does not involve a sonogram, we will show a larger
scale spectrogram of a male voice that is filtered into
seven frequency bands, each about two octaves wide, with
centre frequencies that move up one octave each time. The
voice is that of a West Coast indigenous elder, Herb George,
using a mix of English and Indigenous place names in the
area where he lives. For each of the seven bands, try to
identify which parts of the vocal spectrum you are
hearing, and which band(s) make the speech the most
intelligible. The centre frequency of each band is:
(1) 125 Hz (2) 250
Hz (3) 500 Hz (4) 1
kHz (5) 2 kHz (6) 4
kHz (7) 8 kHz
Male voice filtered into seven bands
an octave apart
Source: Herb George
WSP Van 113 & 114 |
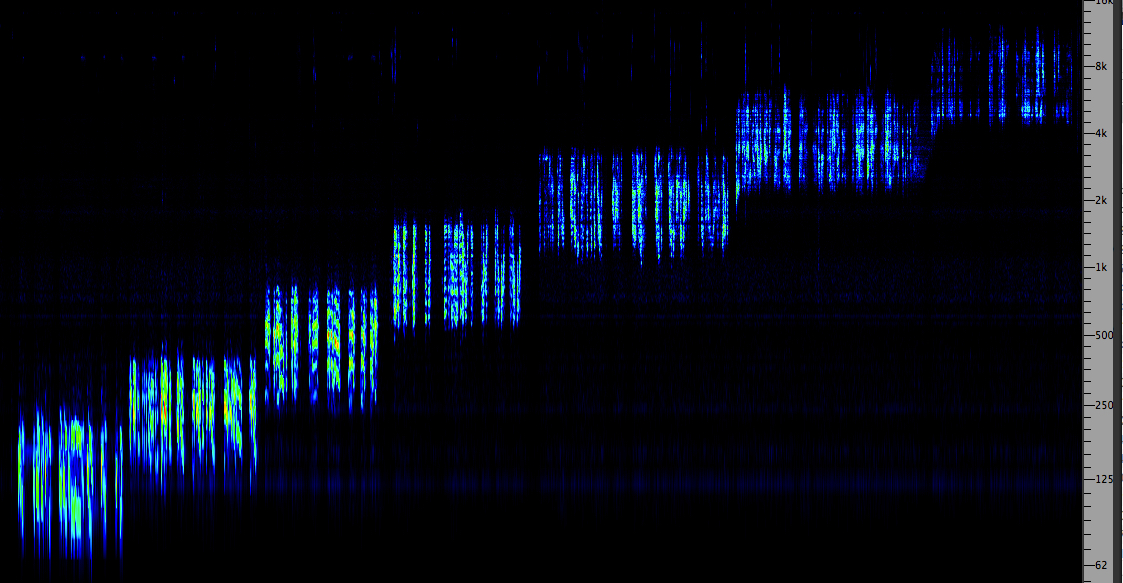
Click to enlarge
|
Here is
what you are most likely to hear in each band according to
its centre frequency:
(1) 125 Hz. You hear the fundamental pitch of
the voice which identifies it as male, and what is
clearest are his pitch inflections (as discussed in the
next section) and their rhythm
(2) 250
Hz. This band is louder and is mainly the lower formants
of the voice but no consonants. Pitch inflections are
clear, but the words are not intelligible, though you hear
when one is emphasized, and the timbre is muffled
(3) 500
Hz. The voice is brighter in this range and vowels can be
recognized, but there are no consonants
(4) 1
kHz. The speech becomes almost understandable even if
you’re hearing non-English words, as you are getting some
vowel and consonant information
(5) 2
kHz. This band is quite quiet and sounds distant, but this
is usually the one where you can understand the speech the
best if you listen carefully; phrases like “name of a
place there”, “and across Belcarra in the inlet” and his
humorous remark about “they say there were lazy people
there” seem quite clear
(6) 4
kHz. In this band you only hear consonants and very little
vowel information
(7) 8
kHz. There are only sibilants in this band and the sound
is the weakest
From this demonstration you can see why the
telephone bandwidth has to include the 2-3 kHz band.
Note that band 5 in the example, from 1-4 kHz, is
where the ear is most sensitive according to the Equal
Loudness Contours that were determined at the
same time as telephone technology was being developed. This
band includes both upper formants in the vowels and some
consonantal information.
To complement the discussion of consonants in
English, you can appreciate the complexity of these place
names from the same speaker. Note that the first three names
have the standard telephone bandwidth (300 Hz - 3 kHz) and
then open up to full bandwidth which makes the sound louder
and brings it closer.
Consonants
in a West Coast Indigenous language
Source: Herb George
WSP Van 113 & 114
|
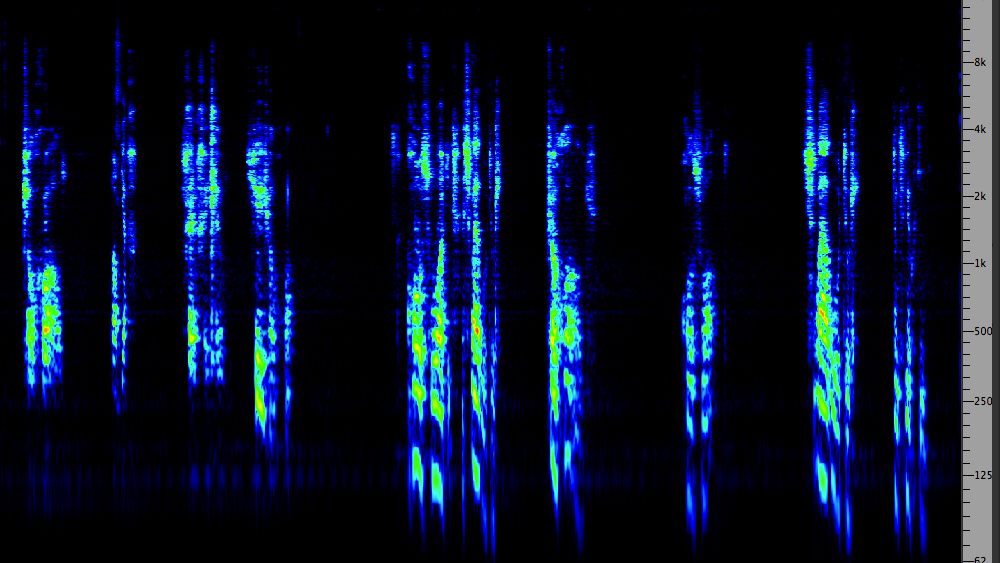
Click
to enlarge
|
Index
D. Voice and soundmaking on a personal
and interpersonal level. Now that we have a grounding
of the acoustics and linguistics of speech, we can switch
levels to consider its larger communicational aspects. A
good place to start is how one’s own soundmaking mediates
the relationship to oneself, to one’s self-image and gender,
and then to the acoustic environment, leading to
interactions with others and larger social groups.
Since sound is a physical phenomenon, our own
soundmaking reflects the whole person, physically and
psychologically. It also reflects the interiority of the
body since all aspects of bodily and mental functioning
influence our ability to make sound. Friends and
acquaintances will easily detect through your voice when
there are changes in your state of health, mood or
personality.
Feedback of our own sounds back to the ears, as well
as feedback from our surrounding environment via reflections
and resonances (as documented in Sound-Environment
Interaction) all play a role in a basic orientation
of the self within a given space. In that module we
presented this example of a voice recorded in different
acoustic spaces, indoors and outdoors, and it’s worth
repeating here now that we have a more detailed
understanding of vocal spectra and resonances. Listen to how
much the timbre of the voice changes in each location (in
fact, some listeners were surprised to learn it was the same
voice).
Voice recorded in different spaces
from program 1,
Soundscapes of Canada
Aural feedback can also be disrupted
in a variety of ways:
- a loss of acoustic feedback at the extremes
of acoustic space,
anechoic conditions (with minimum reflected sound)
and a diffuse
sound field (with minimum absorption such that
sounds have no direction), or ones with high noise levels
such that you cannot hear your own sounds
-
hearing loss can make it difficult to judge the loudness
and clarity of one’s own speech, as can the condition of autophony
described here
- a
temporary disruption can be experienced with earplugs or
headphones; however, the effect is the opposite in each
case: your own sounds seem louder when heard via bone
conduction (termed occlusion) and therefore
you tend to speak more quietly, whereas with headphones
that block the air conduction route, you tend to speak
more loudly
- if a
significant time delay (about 1/4 second) is introduced
into your speech reaching the ears, for instance, via
headphones, you are likely to stop speaking altogether
-
similarly, when people hear a recording of their own
voice, they usually don’t think it “sounds like them”,
because they are used to a mixture of bone conduction and
air conduction in the feedback loop; bone conduction
transmits more low frequencies, and therefore their
absence in a recording makes it seem that your voice is
higher than you think it is (would that affect men more
than women?)
The
Soviet psychologist Lev Vygotsky (1896-1934) researched the
social and cognitive development of children, and one of his
key ideas was that egocentric speech in children
(speaking out loud to only themselves) around the ages of 3
to 4, was a precursor to inner speech and a form of
self-regulation of behaviour. When this kind of speech is
internalized after a few years, it assists listening,
thinking and cognitive development.
Interpersonal interaction and
paralanguage. Non-verbal communication, that is,
without using words, includes bodily and facial movement,
called kinesics, interpersonal distance, called proxemics,
and other sensory forms of behaviour including paralanguage
which is basically how words are spoken.
Paralanguage can be regarded as the analog (i.e.
continuous) aspects of verbal communication, compared with
the discrete, digital form of words. In fact, it is
what links words and phrases together to give them an overall
shape and rhythm. As such, and because of the types of
parameters it includes, it is often regarded as the
“musical” aspects of communication since similar terms apply
to both. In that sense, it describes the form of the
communication, the “how”, rather than the “what” is being
said.
In terms of hemispheric specialization as discussed
in the Sound-Sound Interaction
module, paralanguage is more likely to be processed in the
right hemisphere, compared to the language centres of the
left hemisphere (which is predominant in right-handed
subjects, but can be either right or left in left-handed
subjects). This means it is processed more as shapes and
contours, rather than discrete logical units. It also means
that it is less vulnerable to noise or distortion, since it
is an overall gestalt-like pattern, which is not as easily
degraded, for instance, by missing a word or two.
Also, unlike the digital form of words, analog communication
cannot be self-referential, paradoxical, or self-negating.
A sentence like this one can self-referentially describe
itself as a statement, or even say that it is untrue. On the
other hand, paralanguage and other non-verbal cues can neutralize
or even negate the linguistic content. For instance, a
phrase with negative or critical implications can be
delivered with the right paralanguage that indicates the
speaker is just teasing or joking. In fact, the real
intent is to reaffirm the speaker’s trust in the person the
remark is aimed at. That is, the speaker needs to know that
it won’t be taken the ”wrong way”, a recognition that the
literal meaning is so far from the actual truth that it can
be joked about.
However, as we will see below, when the paralinguistic
form seems to match the content of the communication,
it will be likely be received as genuine and sincere, but
when there is a mismatch, the listener will detect irony,
sarcasm or even misleading intentions and outright
manipulation.
But first, let’s look at the parameters of
paralanguage. Their values can range from normal, to
exaggerated (for emphasis or some effect), to stylized and
ritualistic, as illustrated later.
- pitch: the pattern of pitch
changes is called the vocal inflection, and can
be described as having an average, range and specific
contours; in tonal languages, pitch levels
define the meaning of a word, whereas in Indo-European
languages inflection
clarifies the intent of the communication
- loudness:
also has an average, range and specific in contours that
include patterns of stress on key words
- timbre:
the quality and texture of a voice that gives it a
character that is easy to recognize but difficult to
describe except in general terms (e.g. rough, smooth,
raspy, nasal, etc); vocal timbre is sometimes altered
for a special effect or purpose
- rhythm:
again, we can use the musical terms of tempo
(perhaps measured as words per minute, with an average
and range), as well as patterns of stress that
give it a “metre” (the number of beats per phrase)
- articulation:
the quality of being clear and distinct, ranging to
slurred and indistinct, or smoothly connected versus
jerky and disjointed
- non-verbal
elements: hesitations, emotional elements,
laughter, and other gestures that psychologist Peter
Ostwald calls “infantile gestures” because they can be
observed in babies that are pre-verbal
- silence:
perhaps the most important of all, described by Tom
Bruneau as “a concept and process of mind … an imposed
figure on a mentally imposed ground”
In terms
of Bruneau’s approach to silence, if we limit ourselves for
the moment to just psycho-linguistic silences, the
first of his three levels (the other two being interactive
silences and socio-cultural silences), we can introduce four
aspects of silence in speech that link it to cognitive
processing. According to Bruneau (Journal of
Communication, 23, 1973, pp. 17-46):
- silence is imposed by encoders (i.e.
speakers) to create discontinuity and reduce uncertainty
- silence
is imposed by decoders (i.e. listeners) to create “mind
time” for understanding
- it can
occur in “fast time” through horizontal
sequencing with high frequency of occurrence, short
durations and low emotional intensity
- it can
also occur in “slow time” which reflects semantic
and metaphorical processes, which Bruneau describes as
“organizational, categorical, and spatial movement
through levels of memory”; high sensory moments with
high emotional intensity are experienced in slow time
and/or silence
It will be
useful to keep all of these parameters in mind as you listen
to two interview excerpts, both of which have approximately
the same overall slow tempo, but the role of silence (and
paralanguage in general) is vastly different. The two
examples have been chosen to illustrate our hypothesis about
paralinguistic form matching content, and seeming
appropriate to it.
Does it clarify and put the message into context? What does
it reflect and reveal about the speaker and his/her
relationship to the listener? Is it a form of
metacommunication (i.e. communication about a
communication)?
There are two interviews: (1) a grandmother speaks to her
grandson about the sounds she grew up with on a farm; (2) a
retired policeman offers his views on native land rights
Interview
with a grandmother recalling sounds from her past
|

|
Interview
with a retired policeman about native land rights
|

Click
to enlarge
|
In the first interview excerpt, the
grandmother speaks slowly but steadily with a relaxed tempo,
leaving silent sections where she seems to be recalling
memories (and her grandson was wise not to interrupt those).
However, her pace (which has not be distorted by any
editing) maintains a steady beat and tempo where the most
important words land on the beat (try “conducting” the
recording to see how this works). Each sound memory is given
a vivid aural description with paralinguistic imitations of
the sounds being described, such as sleigh bells “ringing
out”, the train whistle on a “frosty night” which
would “ring across the prairie”, the “purring of a cat” and
the “cackle of hens” which she accompanies with laughter
inviting her listener to join in the amusement.
This interview went on for a very long time, as one memory
led to another, including some unexpected machine sounds
that she found memorable. Her pitch inflections are quite
free for each memory, generally starting higher and
descending to a more intimate level. Overall, she draws the
listener into the memory of each experience, and gives a
clear indication of how she felt about each sound. Her use
of silence is a good example of Bruneau’s concept of “slow
time” which invites reflection and metaphor.
Another example of “slow time” speech is Barry Truax’s
performance of John Cage’s “Lecture on Nothing” from
his book Silence where the text is spread out on the
page to indicate approximate tempo and rhythmic contours
(note, the text starts at 3:40).
In the second interview excerpt, the male speaker’s use of
paralanguage is the complete opposite. As can be seen in the
overall spectrum pattern, his phrases are stiff and
mechanical with no flow. The pauses come in syntactically
inappropriate places, e.g. after a single word, not complete
phrases, as he attempts to maintain control of the subject
matter and allow no intervention or dissent. The sing-song
pitch inflections are repetitive in predictable patterns
that can be arbitrarily applied to any subject, and the
stress points are on arbitrary words, such as “exception”,
“two locations”, “misadventure” and “treaty exists”.
The overall impression is that he is trying to sound
objective and logical (as a professional policeman would be
trained to do), but at key moments there are slips in
objectivity that betray what we come to suspect are his true
feelings. Euphemisms such as “enjoying the treaties”,
mispronouncing “publicity”, correcting his mistake about
“illegally taking it away”, ad hominem (and racist)
characterizations such as “rattled their bones in some type
of a war dance”, clichés such as “at this time” and “in
their wisdom”, all suggest he is repeating an official line
that is intended to hide his own feelings.
As a further example of interpersonal dialogue, you may be
interested in this detailed
analysis of four short interchanges between family
members that reveal a series of dynamic shifts in
paralanguage that reflect underlying issues they are
experiencing.
18.
Personal Listening Experiment. Try
listening to the paralanguage of several different
examples of speech, both on a personal and interpersonal
level, and those found in the media. Refocus your
listening away from the actual content of the spoken
message onto the contours of the phrases and their
rhythmic variations. If you want to be more analytical,
you can use the list of parameters above as a checklist.
If you are coming at this from the electroacoustic side,
you may want to record some examples and loop them similar
to the conversation analysis in the previous link. Ask
yourself what is being communicated that is not directly
in the text? What is being revealed and what remains
hidden? How aware are you of your own use of paralanguage
in typical situations?
Index
E. Soundmaking in cultural contexts.
Voices of power and persuasion.
There are countless examples of vocal styles used publicly
that could be used in this context, but we are going to
listen to some historical recordings that may be less
familiar to you, as well as other instances of stylized
soundmaking.
We begin with a formal political speech given by the
Canadian Prime Minister, William Lyon Mackenzie King, in
1925 to a Liberal convention in Montreal. He uses the
typical kind of projected voice required to be
heard acoustically in a large gathering (it’s unclear
whether any amplification would have been used at that
time, although it was picked up for radio). It is a
classic example of oratory characterized by a raised voice
(higher pitch and loudness), a slow steady beat, and a
series of inflection patterns that start higher and
descend to a cadence. The regular rhythm works to hold
the attention of the audience (in this case a favourable
one), and provides a framework within which a key word or
phrase can be emphasized.
King’s main point is that he needs to have a majority
government in the next election, and so his logical
argument, that extends over two minutes (no sound bites
here), develops in clear stages. It reaches a high point
about 90 seconds in, with the word “majority” on a higher
pitch. This sequence includes the traditional oral
technique of the “list”, a repeated set of similar phrases
that goes through its items one by one so the listener
experiences the time frame, rather than grouping them
together as a logical set – in this case detailing five
consecutive governments in the UK that eventually resulted
in a majority government. He then goes to the US context
where a third party had been rejected in favour of a
strong majority. Also notice how he “speaks into the
applause” to maintain continuity and the energy level.
W.L.M.
King's broadcast speech, 1925
Source: National Library
|

Click
to enlarge
|
Media
analysts often point to Franklin Roosevelt’s “fireside
chats” as being one of the first examples of political
speech adapted to radio, that is, in a relaxed manner
similar to speaking with a small group of friends, not a
large audience. In fact, there were only 30 such broadcasts
by the US President between 1933 and 1944, but they had a
great impact on the country during times of crisis.
A Canadian equivalent is less well known, namely the Rev.
William “Bible Bill” Aberhart, premier of Alberta from
1935-43, and founder of the Social Credit Party, who
combined religion with politics, and began broadcasting from
the Calgary Prophetic Bible Institute as early as 1927. He
had a regular program throughout the 1930s that reached a
wide rural area of the province, where he mixed religion
with a radical critique of the banking system and the
federal government.
In this example, broadcast on Aug. 29, 1937, you can hear
his low-key style in front of an audience in Edmonton that
is clearly designed to resemble a “fireside chat” with a
supportive congregation. In this excerpt he reads from two
letters sent by members of his radio audience (“rapidly” he
says, but actually at a slow steady pace). Note the short
phrases with similar inflection patterns and cadences,
particularly in the text noted on the spectrogram.
Rev. William Aberhart broadcast 1937
Source:
National Library |

Click to enlarge
|
Radio not only produced many
different styles of vocal behaviour, but also created
structures to foreground them, such as the “ad break”. We
presented a detailed analysis of one such break in the Dynamics module where an
announcer brought the listener out of the music and made a
smooth transition into the commercial ad, and then back
into the program content. In this sequence from the 1930s,
a somewhat similar structure was used in a radio drama
program to frame the ad and blur its boundaries.
The framework that is set up is that we’re in the
intermission between two acts of the drama, and that we’ve
gone backstage and can eavesdrop on the two female actors
during the break. The male announcer sets the scene,
coming out of the concluding music, and miraculously we
can hear the actors chatting about the previous scene. It
should be recalled that female voices were not acceptable
as announcers during this period, so an ad sequence with
two female voices was very unusual, though in this case
normalized by their being the same actors as in the play.
Radio voices had to be distinct and expressive
since the actors couldn’t be seen, and so the two females
actors have the stereotypical voices of Sally, the “lady
of the house” (high pitched, smooth timbre, sounding very
educated) and her “maid” Hilda (a broadly defined working
class accent with exaggerated inflections, low pitch and
raspy timbre). They discuss the previous scene in the
garden, eliciting the idea that the maid has a boyfriend,
Henry, whom she wants to impress, but the obstacle she
says is her face.
The lady asks her what soap she is using (the section
shown in the spectrogram), and the maid naively describes
its advertised promises, to which the lady takes on a
didactic stance, offering a medically endorsed (by a male
physician of course) alternative, the Ivory Soap brand.
Then there is more innuendo about Henry, and the announcer
smoothly returns us to the drama cued by “the bell for the
second act”.
Radio drama ad break, Ivory Soap,
1930s
|

Click to enlarge
|
One of the most highly stylized vocal
professions is that of the auctioneer. They are
usually male, and have achieved a high degree of
virtuosity in rapid vocal effects designed to entice the
listener into making a bid on something being sold.
Unlike the previous examples, actual intoning is
used by the auctioneer, that is, placing the words on a
sung pitch which has several advantages. First of all,
the auctioneer can prolong his “patter” much longer than
if he were purely speaking, since less breath is being
expelled. Secondly, this pitch attracts and holds the
listener’s attention and provides a recognizable tonal
centre from which departures can be made, in this case
at the end of each extended breath, the first going up,
the next going down. And thirdly, the sheer pace of the
patter increases the energy level and may induce the
audience’s awe for his virtuosity.
Moreover, this particular auctioneer has mastered the
art of alternating between a rapid rhythmic patter to
hold everyone’s attention, and the “breaks” (which
themselves attract attention) where he cajoles his
target customer with banter. Here his inflections go
much farther up and down than the patter does, and
allows for a free give-and-take plus humorous
interjections. This fellow is highly successful in
building up the bids with each iteration of this pattern
(one of which is shown in the spectrogram), until he
finally gets a high price for what he is selling (in
this case a pumpkin). As a footnote, the previous
unsuccessful auctioneer got a 25 cent bid, and this guy
got $2.50!
Auctioneer
Source: WSP Van 123 take 13 |

Click to enlarge
|
So
far we have only given examples of the solo voice, but
there are many instances where multiple voices
join together, not just in unison (which is also
impressive) but in competition. Sports events are well
known examples of this, but in the next example we get
a more intimate situation, a local softball game where
the team members and fans are particularly vocal about
encouraging their own team members, and intimidating
their opponents.
Paralanguage clearly
dominates semantic content – the form of the
communication is more important, and its goal is to
hype one player (the pitcher or the batter) and to
diss the other. Short punchy repeated phrases are
used, such as “Come on now, like you can … hum in
there” to the pitcher Benny, or “you watch ‘em now
fella” to the batter, Al.
The second example does not have opposing teams, but
has every player vying with everyone else. This is a
historic recording from the trading floor of the
Vancouver Stock Exchange, at a time when bids and
offers had to be shouted out by each trader (now
superseded of course by computers). The example is
remarkable for how different each person had to sound
to be noticed above all the others and the general
din. All of the paralinguistic cues are on display,
pitch inflections, timbre and loudness, in a perfect
symbol of market capitalism. We might even compare
this behaviour to the Acoustic
Niche Hypothesis where each species has
its own frequency band.
Softball
game
Source: WSP Van 107 take 3 |
Trading
floor, Vancouver Stock Exchange, 1973
Source: WSP Van 30 take 2 |
A unique
form of collective soundmaking that few people have
experienced is called glossolalia, commonly called
“speaking in tongues” as practiced by certain evangelical
congregations. The idea is not necessarily having the
ability to speak in a different language (which is the usual
interpretation of the Biblical account of the disciples at
Pentecost being given the power to go forth to other lands
and preach). Most studies find that the vocalization in
glossolalia is made up of phonemes and syllables in the
speaker’s own language, and so it represents a kind of free
vocal improvisation.
In this example, recorded in a church in Vancouver, the
individual voices can be clearly heard overlapping in a
random fashion. We won’t speculate on the religious aspects
of the practice, but simply note that public soundmaking
opportunities are generally regulated in an orderly fashion,
and other than unison behaviour at specific moments, there
are few opportunities to have complete vocal freedom in a
public context that is clearly devoid of any sense of
negative emotion (which leaves out major sports events). The
ability with glossolalia to maintain such vocalizations for
a long period indicates that it is not stressing the body,
but rather providing a safe outlet for self-expression
within a community group.
Group
participation in glossolalia at a Vancouver church
F. Cross-cultural forms of vocal
soundmaking. In many cultures, functional and
musical vocalization practices – which are usually deeply
intertwined – are highly complex and reveal a seemingly
infinite variety of vocal possibilities. Some of these
practices are endangered in the contemporary world, others
have been revived to some extent by enthusiastic
followers, and still others have managed to transfer
themselves through evolution into contemporary
multi-cultural practice.
The functional aspect of the various types of soundmaking
usually reflect and utilize the typical acoustic spaces they are
found in, and have clearly evolved in relation to them to
the point where they can be called languages. For
instance, the whistling languages found in many
parts of the world, the best known being in the Canary
Islands, are designed to communicate across mountainous
valleys since high frequencies will carry well in
the absence of absorbing obstacles, similar to the Swedish
examples of kulning presented below.
African drumming languages, often referred to as
talking drums, can also communicate over long distances
through the jungle and be relayed even farther. They can
imitate the tonal patterns of spoken language
through the resonances of the log drums. Of the countless
other examples we could draw on, here are just four
traditions from other cultures that we can briefly
introduce you to, in the hope that they will inspire you
to investigate them and others more fully.
Inuit. The traditional competitive tradition of
Inuit throat singing, known as katajjaq,
in the Canadian high arctic, was usually practiced by two
women facing each other at a very close distance,
sometimes close enough to use their partner’s mouth as a
resonator. They took turns uttering complex rhythmic
sounds on both the inhale and exhale of the breath,
filling in the gaps in the other’s sound. These sounds
were sometimes intended to imitate those of nature, or
even machines in more recent times. It was performed by
both adult women and young girls who could adapt the
practice to exchange gossip about their boyfriends, for
instance. The development of such diaphragmatic breathing
was probably beneficial for a cold climate. The cycle
ended when one ran out of breath, and laughter erupted as
in this recording.
Inuit
throat singing
|
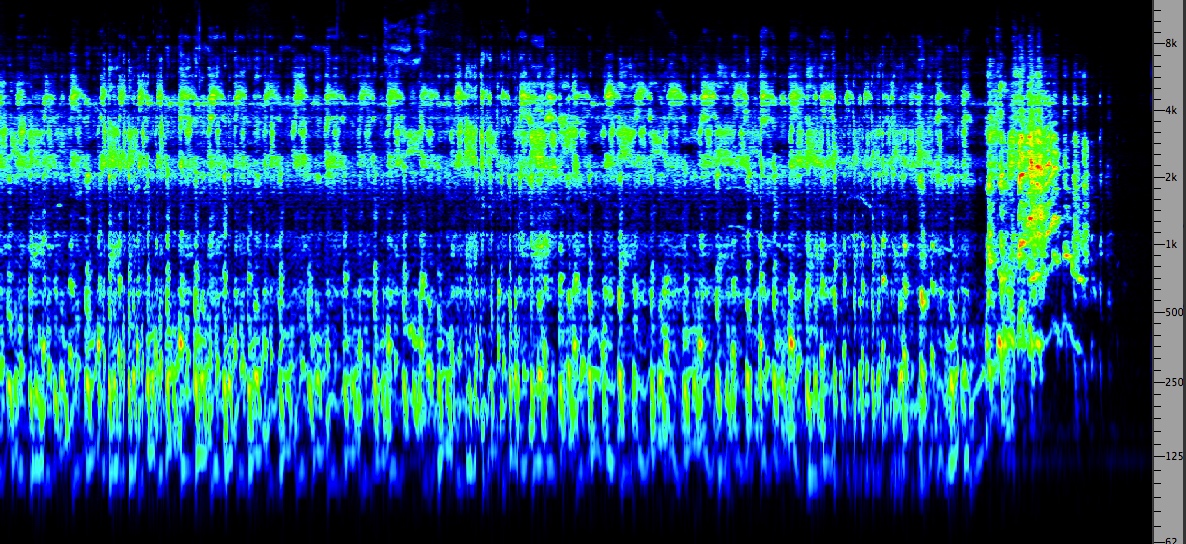
Click
to enlarge
|
Sweden. In the north of Sweden, the
women who were tending small herds of cows and sheep in the
mountainous regions, developed an amazing singing style
called kulning that was partly functional – to call
their animals and to communicate with others across a
valley, for instance – and highly musical with extremely
high pitches and precise intervals produced with what is
called head voice. In some examples, the inflections
of speech directed at the animals flowed smoothly into these
sung pitch patterns as in the first example. In others, the
melodic lines are entirely sung with intricate ornamentation
as in the second example, perhaps reflecting the isolation
being experienced.
These are just two examples of those recorded by the Swedish
musician Bengt Hambraeus in the late 1940s and early 50s,
transmitted by a telephone line back to Stockholm. In some
recordings you can hear an echo from across the valley. With
no barrier to absorb the sound, these high pitches actually
carried farther than low-pitch sounds. The tradition
gradually disappeared from actual herding practice, but has
recently been revived by younger singers studying the
tradition.
Swedish
mountain shepherdess calls to her animals
|
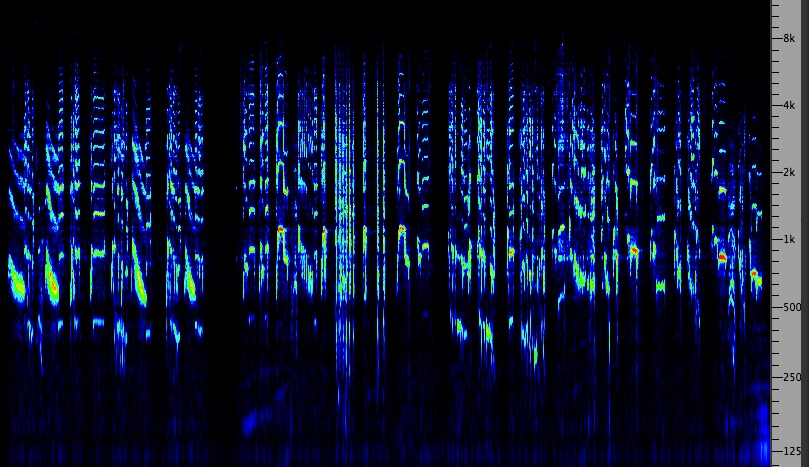
|
Swedish
mountain shepherdess singing
Source:
Bengt Hambraeus
|
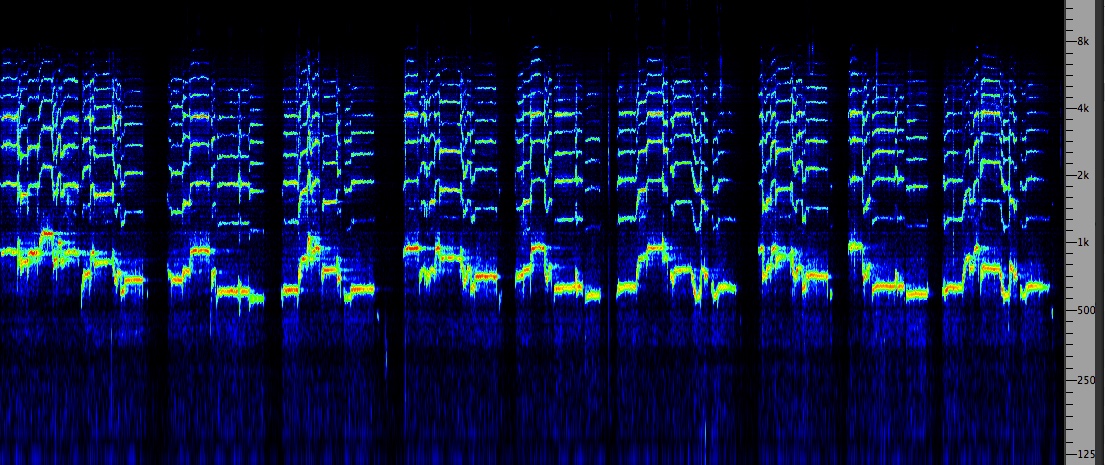
Click
to enlarge
|
Pygmy. The various Pygmy cultures in
sub-Saharan Africa, such as the Aka and Baka peoples, have
become well-known for their contrapuntal music and relaxed
vocal style. The first recording with two young girls shows
that even the children can master the interweaving of two
complex vocal lines, sung on the breath, each with very
precise musical intervals. The second example is a group of
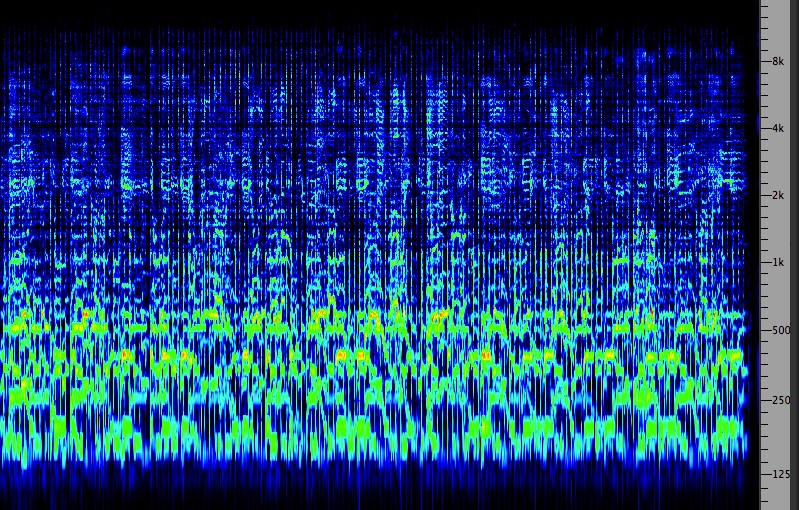
men and boys who have returned from the hunt, and shows an
interlocking rhythmic style where each person contributes
their own line according to their ability. Some commentators
such as Colin Turnbull and Alan Lomax have suggested a
correlation between this musical style and their
traditional, communal lifestyle. The French
ethnomusicologist, Simha Arom, has published many sound
recordings such as these.
Two pygmy girls singing in
counterpoint
|
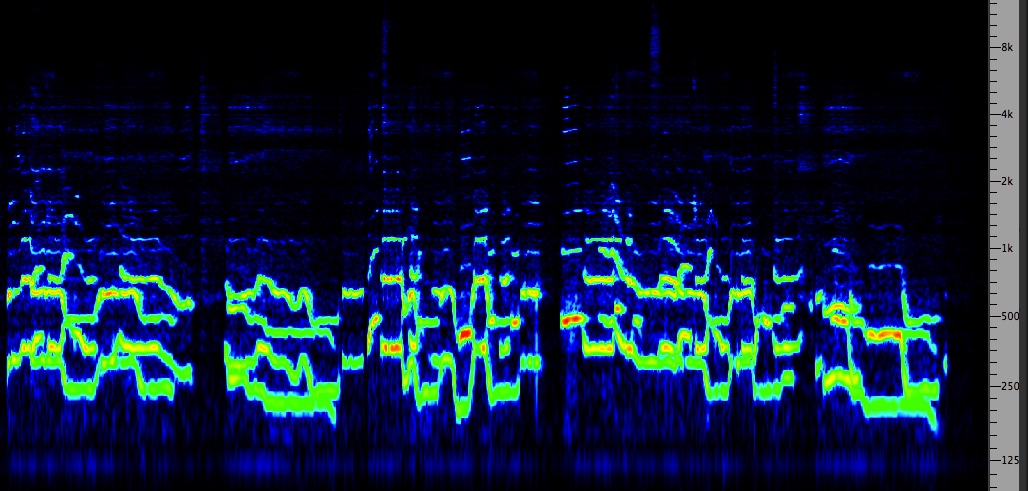
|
Pygmy men and boys singing after the
hunt
Source: Simha Arom
|
Click to enlarge
|
Tuvan. The nomadic Tuvan people
of Central Asia developed a form of throat singing that
can produce overtones and multiphonics, that is,
overtones so strong they can be heard as multiple pitches.
The high pitches that you hear in this brief example are
produced by a manipulation of the tongue at the front of
the mouth at the same time as the throat is being
constricted at the back. As with the Inuit, circular
breathing allows the sound to be sustained for long
periods of time.
Tuvan throat singing
|
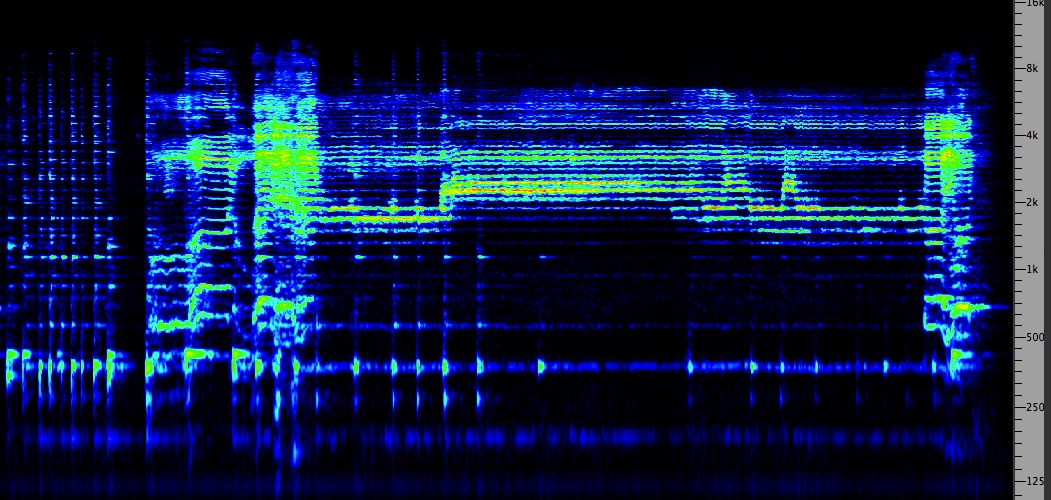
Last sequence of the recording;
click to enlarge
|
Index
Q. Try this review quiz to
test your comprehension of the above material,
and perhaps to clarify some distinctions you may
have missed.
home
