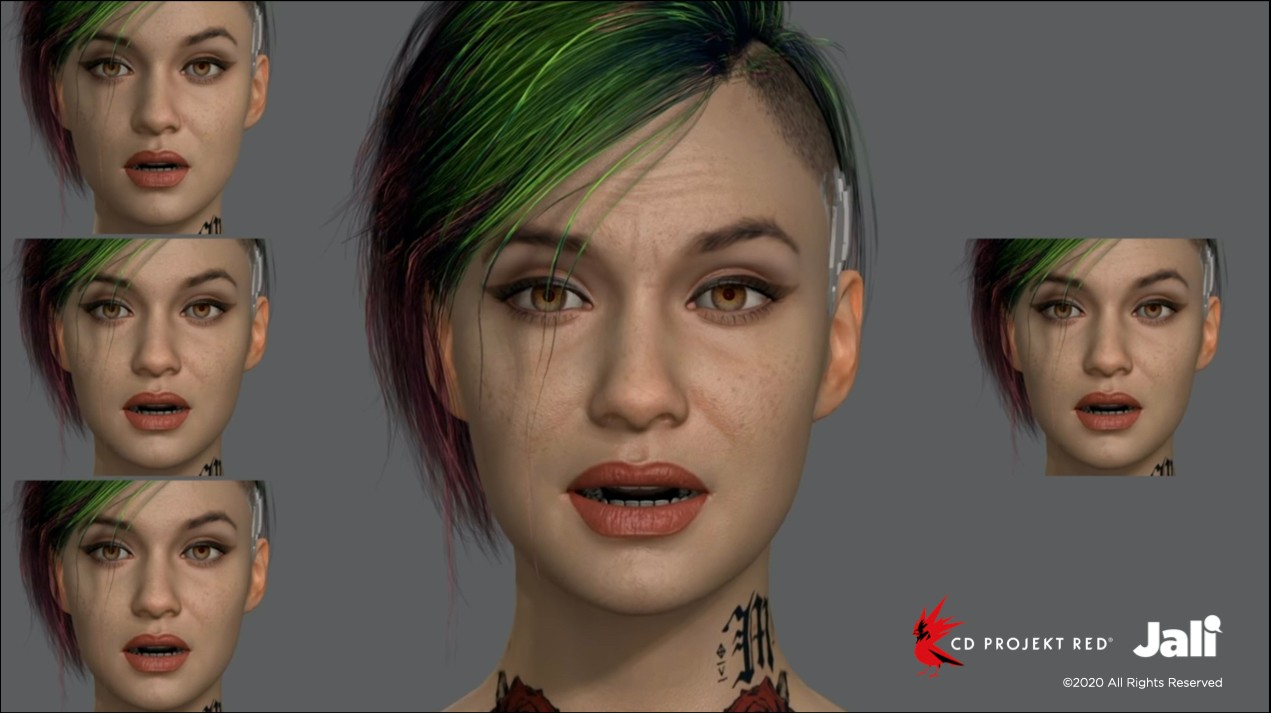

The JALI technology allows 3D character faces to automatically perform the audio dialogue that is provided, with a high degree of accuracy. This eliminates the need for facial motion capture – when animations are created using facial expressions captured from an actor’s performance of the same dialogue – or the long hours to animate a scene, one key frame at a time. That said, the JALI technology is also able to work in tandem with motion capture techniques.
“Human speech contains a huge amount of information,” notes Fiume. “We can extract expression and emphasis from human speech in many different languages and, putting that information together with a text transcript, we can animate a 3D virtual model of the face.
“In effect, we transform a voice actor into a synthetic facial performer in a virtual environment.”
This is a game-changer (pardon the pun) as it allows game designers to add more complexity to their virtual world without being limited by their animation capacity. This creates opportunities to include more characters, varying facial structures and speaking styles, longer storylines, multiple ways for conversations to unfold, and the ability to switch between languages. JALI allows character speech performances to seamlessly adapt to the situation and the choices of the player, making games like Cyberpunk 2077 very appealing.